
Elena Canorea
Communications Lead
Durante los últimos años hemos visto como los avances en la inteligencia artificial y el Machine Learning han conseguido la aparición de grandes Foundations Models que se entrenan previamente con una gran cantidad de datos.
Analizamos en qué consisten, sus ventajas al usarlos en Azure Machine Learning y cómo usarlos.
Los Foundation Models o modelos básicos sirven como punto de partida para desarrollar modelos especializados, los cuales se pueden adaptar fácilmente a múltiples aplicaciones en diferentes industrias. De hecho, estos modelos se han posicionado como una oportunidad única para que las empresas creen y los utilicen en sus cargas de trabajo de Deep Learning.
Al utilizarlos en Azure Machine Learning se proporcionan funcionalidades nativas de Azure ML que permiten poner en funcionamiento estos modelos de código abierto a escala. Así se pueden integrar fácilmente en las aplicaciones de negocio, además de incluir capacidades como:
Se trata de un centro para encontrar Foundation Models en Azure Machine Learning y supone un punto de partida para explorar estos modelos. Podrás buscar y filtrar modelos según las tareas para los que están capacitados. Por ahora, solo hay modelos que trabajan con texto, pero también se han desplegado whishper que son capaces de trabajar con audio.
Este catálogo tiene, por el momento, dos colecciones de modelos: Modelos de código abierto seleccionados por Azure Machine Learning (listo para su uso inmediato y optimizados, con soporte nativo y fácilmente migrables) y Modelos Transformers del centro HuggingFace (miles de modelos para inferencia en tiempo real con puntos finales online).
Este último servicio, es el creador de la principal biblioteca de código abierto para crear modelos de ML de última generación. Permite implementar modelos de aprendizaje automático en un punto de conexión dedicado con la infraestructura de nivel empresarial de Azure. Permite elegir entre decenas de miles de modelos de ML para procesamiento de lenguaje natural, audio y visión artificial para acelerar la carga de trabajo. Además, agiliza la inferencia con una implementación sencilla y ayuda a mantener nuestros datos privados y seguros.
Como decíamos más arriba, los Foundation Models en Azure Machine Learning proporcionan funcionalidades nativas para descubrir, evaluar, ajustar, implementar y poner en funcionamiento estos modelos de código abierto.
Para poder acceder a estos modelos, deberás entrar en Azure Machine Learning Studio, un centro para descubrir el catálogo de los modelos básicos. Ahí verás los modelos más populares, además de LLM de código abierto y más tareas que se incluirán próximamente.
Tendrás la opción de filtrar por tarea o licencia para, a continuación, seleccionar un nombre de modelo específico, donde podrás leer una tarjeta en la que se describen los detalles del modelo:
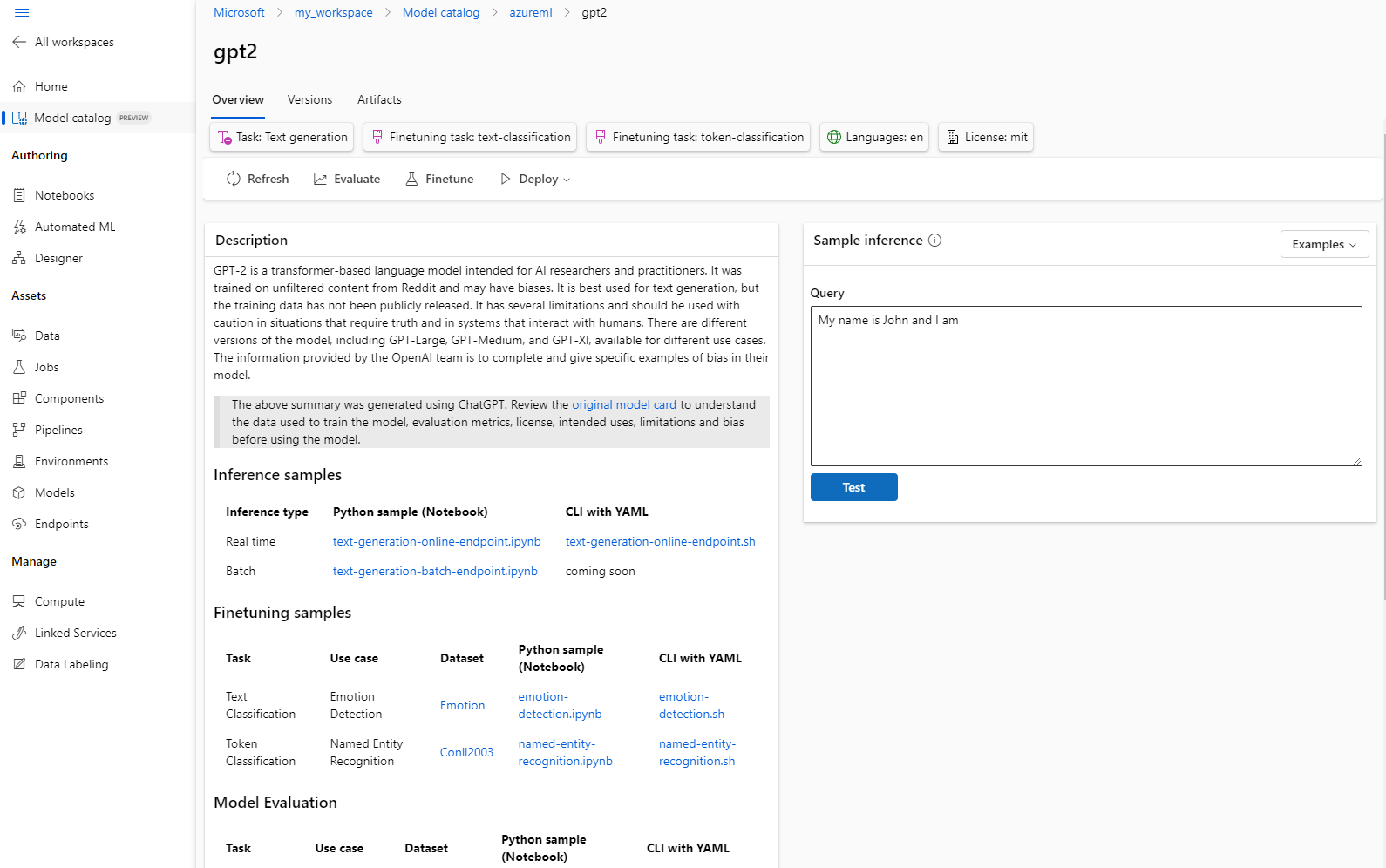
Podrás probar rápidamente cualquier modelo usando el widget de inferencia de muestra gracias a la tarjeta del modelo, la cual te dará tu propia entrada de ejemplo para probar el resultado.
Podrás evaluar un modelo comparándolo con el conjunto de tus datos de prueba de dos formas: mediante el asistente “Evaluate UI Wizard” o mediante ejemplos basados en código.
En la evaluación mediante el Asistente de UI, cada modelo se puede evaluar para una tarea específica de inferencia:
Para mejorar el rendimiento del modelo en tu carga de trabajo, puedes hacer ajustes usando tus propios datos de entrenamiento de forma sencilla usando el asistente Finetune o mediante el uso de ejemplos basados en código vinculados desde la tarjeta del modelo.
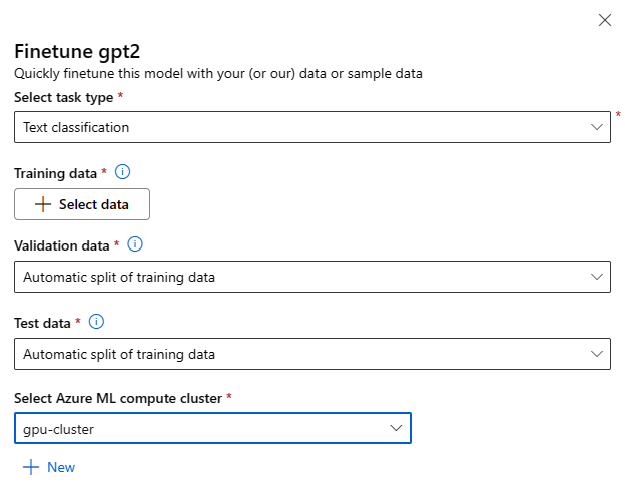
Cada modelo preentrenado del catálogo se puede ajustar para un conjunto específico de tareas, solo tienes que seleccionarla en el menú desplegable. Pasa los datos de entrenamiento cargando un archivo local o seleccionando un conjunto de datos de tu espacio de trabajo.
A continuación, pasa los datos a validar seleccionando “División automática”. También pasa los datos de prueba que te quieras usar para evaluar el modelo ya ajustado. Se reservará una división automática de los datos de entrenamiento para la prueba.
Después, proporciona el clúster del proceso que quieras ajustar, donde recomendamos usar SKU de cómputo con GPU A100/V100. Por último, selecciona “Finalizar” en el asistente para enviar tu trabajo de ajuste fino.
Encontrarás varios parámetros de ajuste avanzado, como la tasa de aprendizaje, las épocas, el tamaño del lote, etc.
En Plain Concepts ayudamos a las empresas a gestionar sus proyectos de Machine Learning proporcionando orientación experta sobre IA y MLOps, incluida la evaluación de las capacidades actuales y la aplicación de prácticas estándar del sector para mantener un entorno de ML listo para la producción.
Somos una de las primeras empresas en obtener la AI and Machine Learning on Microsoft Azure Advanced Specialization, por lo que podemos ayudarte en la implementación de soluciones para el ciclo de vida del aprendizaje automático y las aplicaciones impulsadas por IA.
Si estás listo para comenzar o avanzar en tu proyecto, pero no sabes cómo, podemos ayudarte. Contacta con nosotros y nuestros expertos estudiarán tu caso para encontrar la forma de sacar el mayor partido a tu negocio.
Elena Canorea
Communications Lead
