
Javier Carnero
Research Manager at Plain Concepts
En el equipo de Research de Plain Concepts estamos acostumbrados a buscar soluciones innovadoras para nuestros clientes, y en gran parte de esas ocasiones involucramos inteligencia artificial. Continuamente, vemos que su adopción masiva se enfrenta retos críticos cuando depende exclusivamente de la nube, en concreto: costes recurrentes elevados, exposición de datos sensibles, latencia de red y limitaciones reales de escalabilidad en organizaciones con cientos de usuarios.
Debido a esto, en el equipo llevamos unos meses trabajando con algunos de nuestros clientes en una nueva arquitectura híbrida que combina lo mejor de la IA en la nube con la potencia de los dispositivos personales en dispositivos que permiten ejecutar modelos de IA localmente, aprovechando la capacidad de cómputo distribuido y reduciendo costes operativos.
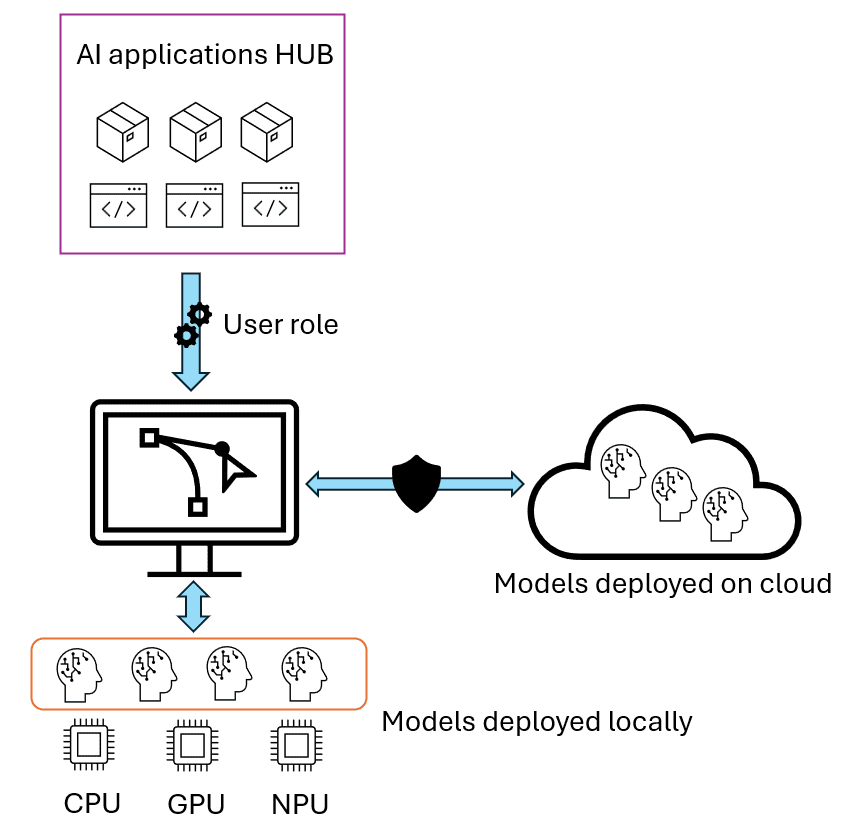
En esta arquitectura, las aplicaciones y modelos de IA se encuentran inicialmente disponibles para ser desplegadas en un HUB en la nube, que realiza un despliegue selectivo: Modelos complejos en la nube para casos críticos, modelos optimizados en local para el uso diario. Así, las aplicaciones se ejecutan de forma distribuida: Cada dispositivo local aporta capacidad de inferencia, eliminando cuellos de botella centralizados. Además, se tiene un control granular: Gestión completa sobre qué datos, modelos y usuarios acceden a cada recurso.
Por ejemplo, imaginemos una empresa de medios como MediaPro, que necesita procesar grandes volúmenes de vídeo y audio para tareas como transcripción, subtitulado automático o generación de resúmenes. Con una arquitectura híbrida, los modelos más pesados (por ejemplo, para análisis semántico avanzado) pueden residir en la nube y ser accesibles solo para perfiles críticos. Mientras tanto, tareas recurrentes y menos exigentes (como la transcripción básica o la clasificación de contenido) se ejecutan en local, aprovechando la aceleración por hardware de los portátiles de los empleados. Esto permite escalar la solución a toda la organización sin incurrir en costes prohibitivos ni comprometer la privacidad de los datos.
Esta arquitectura se basa en el uso de portátiles Intel Core™ Ultra con NPU (Neural Processing Unit) y GPU integradas
Éstos portátiles con aceleradores integrados abren una nueva arquitectura híbrida que combina lo mejor de ambos mundos: la potencia del cloud para cargas críticas y la eficiencia del edge computing para casos de uso cotidianos.
La NPU (Neural Processing Unit) es un procesador dedicado específicamente a la ejecución eficiente de modelos de inteligencia artificial, especialmente aquellos que requieren inferencias recurrentes o en segundo plano. Su diseño está orientado a maximizar la eficiencia energética, permitiendo ejecutar tareas de IA de forma sostenida sin comprometer la autonomía del dispositivo. La NPU es ideal para cargas como:
En palabras de los propios ingenieros de Intel, la NPU actúa como el “corredor de maratón” del sistema: gestiona cargas de trabajo de larga duración de manera sostenible, asegurando que la batería del portátil se mantenga durante toda la jornada laboral, incluso en escenarios de uso intensivo de IA.
La arquitectura de los Intel Core Ultra distribuye las tareas de IA según su naturaleza y requisitos de rendimiento:
| Fast Response | Performance Parallelism & Throughput | Dedicated Low Power AI Engine |
| Ideal for lightweight, single-inference, low-latency AI tasks | Ideal for AI-infused Media/3D/Render pipelines | Ideal for sustained AI and AI offload |
| P-core & E-core CPU Architecture | Xe2 GPU Architecture | NCEs, Neural Compute Engines |
| VNNI & AVX, AI Instructions | XMX, Xe Matrix Extension | Efficiency of matrix compute |
Los portátiles Intel Core™ Ultra ejecutan modelos de IA localmente usando frameworks compatibles como OpenVINO, ONNX Runtime, Hugging Face Optimum Intel y Azure Foundry Local.
Foundry Local ejecuta modelos de lenguaje directamente en el cliente, optimizando automáticamente para CPU o GPU.
Ejemplo de instalación y ejecución:
winget install Microsoft.FoundryLocal
foundry model run phi-3.5-mini
Foundry Local ofrece instalación inmediata y gestión transparente con privacidad total, aunque actualmente está en preview con un catálogo limitado de modelos y sin soporte para NPU.
OpenVINO es el toolkit principal para aprovechar la NPU Intel.
Ejemplo de detección de dispositivos:
import openvino as ov
core = ov.Core()
core.available_devices # ['CPU', 'GPU', 'NPU']
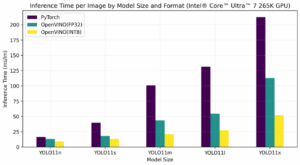
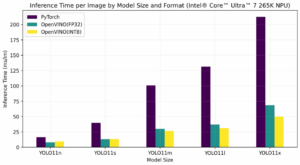
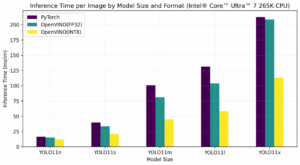
La compresión es clave para la ejecución eficiente en dispositivos locales. OpenVINO con NNCF permite reducir modelos sin pérdida significativa de precisión.
Resultados de optimización YOLOv8:

Comparativa de rendimiento por dispositivo:
| Dispositivo | Mejora con optimización | Eficiencia energética |
|---|---|---|
| CPU | 2x más rápido | Estándar |
| GPU | 4x más rápido | Alta |
| NPU | 3x más rápido | Máxima (~13W vs 20W) |
En el equipo de Research, una de las principales tecnologías que desarrollamos es Evergine, un motor gráfico enfocado en la renderización 3D para aplicaciones industriales. Es común en nuestro trabajo la necesidad de integrar modelos de IA con las aplicaciones de Evergine de forma que permiten una comprensión más profunda del entorno, mejorando la interacción y la visualización de datos complejos.
Como prueba de concepto para poner a prueba las capacidades de los portátiles Intel Core Ultra, hemos desarrollado un entorno 3D fotorealista que utiliza la tecnología de Gaussian Splatting para renderizar una sala de estar fotorealista en tiempo real, a la vez que integra un modelo de detección de objetos para identificar y clasificar elementos en la escena en tiempo real.
Mientras el usuario se mueve por la escena, esta es renderizada en la GPU, y en paralelo el modelo de detección de objetos se ejecuta en la NPU, lo que permite una identificación y clasificación más rápida y eficiente de los elementos, ganando tanto en tiempo de ejecución como en consumo energético, sin salir del entorno local.


Intel Core Ultra laptops make it possible to run enterprise-grade virtual assistants with RAG (Retrieval-Augmented Generation) fully on-device, distributing workloads across the different accelerators:
Distribuir la carga entre los diferentes aceleradores en local nos ofrece una mayor eficiencia energética, ya que la NPU consume ~13W vs 20W de CPU/GPU.
WebNN permite ejecutar modelos de IA directamente en aplicaciones web aprovechando la aceleración por hardware, sin instalaciones adicionales. Esto nos permite hacer despliegues instantáneos vía web, privacidad completa (procesamiento local), y aceleración automática según el hardware disponible.
Algunos ejemplos:
Generación de imágenes (Stable Diffusion Turbo en GPU):
Transcripción de voz (Whisper en NPU):
Segmentación de imágenes (Segment Anything):
Gimp integra plugins de IA que aprovechan los aceleradores Intel para tareas avanzadas. Además, estos plugins permiten elegir dinámicamente el acelerador (CPU/GPU/NPU) según la carga de trabajo.
Actualmente hay tres plugins disponibles:
La arquitectura híbrida de IA sobre Intel AI PC ofrece beneficios concretos y cuantificables:
| Concepto | Ejecución en cloud | Ejecución en local (Intel Core Ultra) |
|---|---|---|
| Coste por uso | Variable (por token/hora) | Cero (incluido en dispositivo) |
| Latencia de respuesta | Alta (red + backend) | Baja (en dispositivo) |
| Coste total mensual (100 usuarios) | 1.500–3.000 € | 0–100 € (soporte/IT) |
| Dependencia de conectividad | Crítica | Opcional |
La historia de la computación está marcada por grandes cambios de paradigma. La llegada del ordenador personal democratizó la tecnología. Hoy, la IA está viviendo una transición similar: del cloud al endpoint, al dispositivo personal.
Los portátiles Intel Core Ultra con NPU representan este cambio, ofreciendo:
Las empresas pueden construir un modelo de IA distribuido, sostenible y rentable, combinando la potencia del cloud con la eficiencia del edge.
Estamos ante una nueva era de la inteligencia artificial, donde la capacidad de innovar estará ligada a ejecutar IA allí donde realmente se generan y utilizan los datos: en el propio dispositivo del usuario.
Nota del autor: Parte del estudio y los experimentos que han servido de base para este artículo fueron presentados en una charla técnica durante dotNET 2025 Madrid, impartida conjuntamente por Ana Escobar (ana.escobar.acunas@intel.com) y el autor. Muchos de los vídeos, demostraciones y datos incluidos en este trabajo no habrían sido posibles sin la inestimable colaboración y experiencia de Ana, a quien agradezco especialmente su apoyo.
Javier Carnero
Research Manager at Plain Concepts