
Elena Canorea
Communications Lead
Esta versión trae una gran cantidad de características mejoradas en varios módulos clave de Sidra, especialmente en la ingesta de datos y el espacio de servicio de Model Serving. Las mejoras en la ingesta de datos también se han llevado al modelo de conectores de interfaz de usuario (plugin), por lo que las nuevas versiones de los conectores incluyen múltiples mejoras de rendimiento y funcionalidad
El enfoque de plugins utilizado para los conectores (configuración de nuevos procesos de entrada de datos) también se ha adaptado al espacio de la Aplicación Cliente. De esta forma, con este modelo, cualquier nueva Aplicación Cliente en Sidra que se desarrolle siguiendo este enfoque de paquete de plugins, puede crearse y desplegarse fácilmente desde una interfaz web.
Además, esta versión viene con importantes características en torno a la operatividad de la plataforma, tanto desde la perspectiva web, pero también desde la perspectiva de otras herramientas operativas, como la automatización de la supervisión de los servicios de la API y los reinicios.
Con este lanzamiento, también nos complace anunciar nuestro nuevo portal de ideas de Sidra, donde puedes tener un lugar para compartir y votar ideas para Sidra.
Mejoras funcionales y de rendimiento de la toma de datos
Una gran parte del esfuerzo de ingeniería en esta versión se ha dedicado a revisar y actualizar importantes mejoras funcionales y de rendimiento en las canalizaciones de admisión de datos. Estas nuevas características se han introducido para dar soporte a ciertos escenarios nuevos, así como para mejorar sustancialmente el rendimiento de los procesos de admisión de datos.
A continuación, os dejamos una lista con todas las actualizaciones incluidas en esta función:
NeedReload a True. Sin embargo, esto no era suficiente para forzar una recarga hasta que el campo EnableReload se estableciera en 1 en la tabla EntityDeltaLoad. Esta función incluye ahora una mejora por la que se utiliza una nueva propiedad AutomaticReload que se rellena en el campo AdditionalProperties Entity field. De esta forma, cuando el campo AutomaticReload es verdadero, y NeedReload es verdadero, se dispara una condición para recargar los datos, sin importar el valor de EnableReload.Puedes ver más información sobre estos campos en las páginas de documentación de EntityDeltaLoad y Mecanismo de carga incremental de SQL Server .En la versión anterior de Sidra, 2021.R1, se lanzó la función de interfaz de usuario de conectores de datos para simplificar la configuración de nuevos procesos de admisión de datos a través de Sidra Web. Aunque se utiliza el término conectores para referirse a los diferentes programas para conectarse a los sistemas de origen de datos (por ejemplo, SQL Server, base de datos Azure SQL), internamente dichos programas se empaquetan en un modelo de plugin. Para crear y configurar los procesos de ingesta de datos, utilizamos plugins de tipo connector. Dichos plugins son conjuntos de código que se descargan, instalan y ejecutan desde la interfaz web.
Una ventaja muy importante de los plugins es que su ciclo de vida de lanzamiento puede desvincularse del ciclo de vida de los lanzamientos principales de Sidra, lo que aumenta la velocidad de entrega de nuevos plugins y reduce las dependencias. Puedes ver más detalles sobre el enfoque de los plugins documentación de los conectores de Sidra. Con 2021.R2 se ha adaptado toda la gestión y arquitectura de plugins para permitir el despliegue de aplicaciones cliente desde la web. En este caso los plugins utilizados son del tipo Client Application.
Este es un logro importante de esta versión. A lo largo de las siguientes versiones de Sidra, tenemos previsto anunciar y lanzar nuevos plugins de tipo Client Application.
Vamos a migrar las plantillas de Aplicaciones de Cliente existentes con este nuevo modelo de plugin, de modo que la implantación (a partir de una plantilla determinada) de una Aplicación de Cliente de Sidra pueda realizarse simplemente rellenando un conjunto de pasos den el asistente de la interfaz de usuario. El mismo enfoque está listo para ser seguido también para la implementación de futuras Aplicaciones Cliente de clientes.
Además de esto, ahora Sidra Web incorpora una página de detalle de la Aplicación Cliente que expone la información de metadatos sobre cada Aplicación Cliente. Al hacer clic en cada Aplicación Cliente, se abre una página de detalle, que muestra campos de metadatos de manera similar a los del Catálogo de Datos para Proveedores y Entidades: descripción breve, propietario de la Aplicación y un campo de descripción detallada que permite su edición.
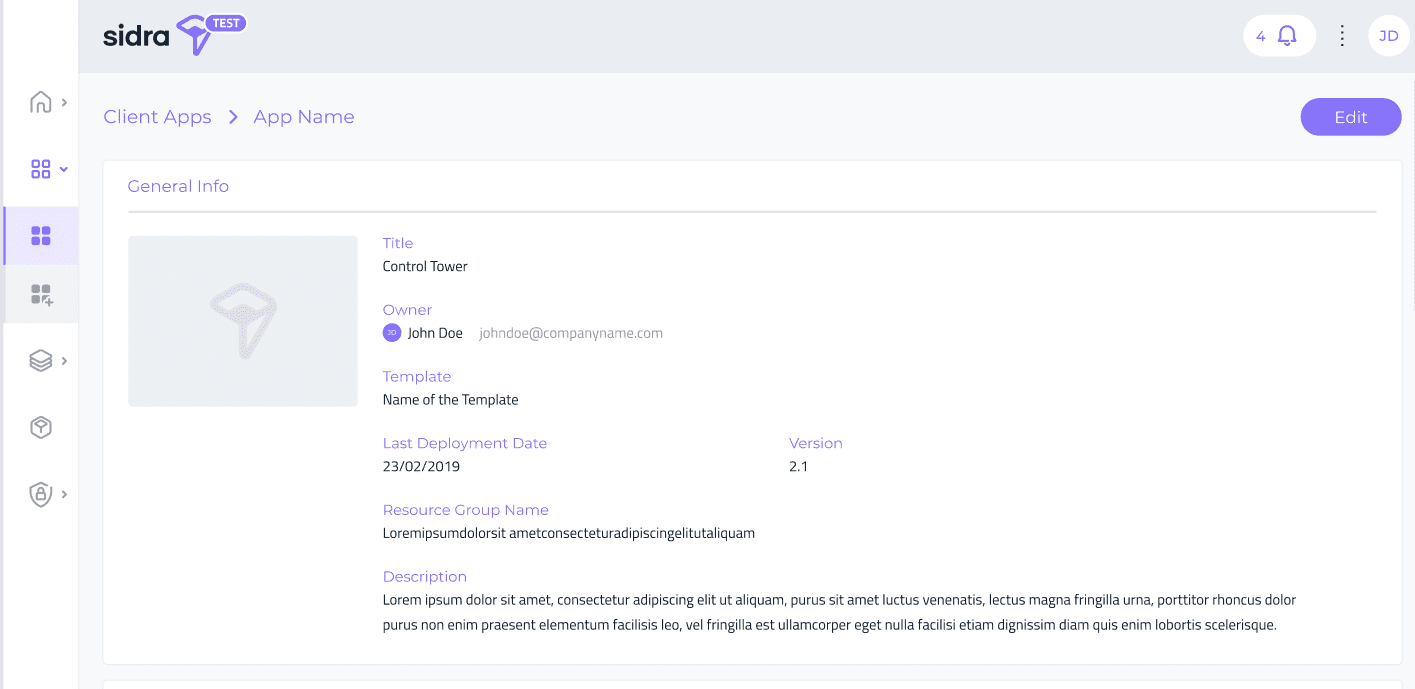
Esta vista será el punto de entrada para añadir, en versiones posteriores, más detalles operativos y acciones en las Aplicaciones Cliente.
La arquitectura de Sidra se basa en el concepto de unidad de almacenamiento de datos (DSU) como unidad de infraestructura atómica para el procesamiento de datos (ingestade datos, almacenamiento de datos, transformación de datos, indexación de datos) en Sidra. Cada Unidad de Almacenamiento de Datos permite la separación de dominio funcional o emprearial e incluso la segregación regional de datos si es necesario.
Tras el lanzamiento de la herramienta Sidra CLI para la instalación y el despliegue de Sidra, quedaba pendiente la migración del nuevo proceso de despliegue para poder instalar por separado una segunda o posteriores DSU. Esta función incorpora un script de despliegue específico y un proceso para instalar DSU adicionales además de la DSU predeterminada que viene con cualquier instalación de Sidra. Esta característica está sujeta a la disponibilidad de los servicios Azure de la Unidad de Almacenamiento de Datos dependiente en cada región, y esto incluye la disponibilidad regional del servicio Databricks.
Esta función permite desacoplar los ciclos de desarrollo y lanzamiento de plugins, tanto para los conectores como para las Aplicaciones Cliente, gestionando la visibilidad de cualquier plugin y versión de plugin a nivel de cada cliente e instalación de Sidra. A través de esta función, ahora es posible que los clientes limiten la visibilidad de los plugins y las versiones de los mismos a solo determinadas instalaciones de Sidra. Esto permite escenarios de pruebas tempranas y la validación de nuevos plugins que se están desarrollando.
La tabla TypeTranslation almacena las reglas de mapeo y transformación de tipos para las diferentes etapas del procesamiento de atributos cuando las fuentes de datos se configuran e ingieren en Sidra. Puedes ver más información sobre estas tablas en las páginas Data ingestion documentation y About Sidra connectors.
El uso de dicha tabla se ha ampliado para albergar todo tipo de reglas de mapeo y transformación de tipos entre los sistemas fuente de las bases de datos, ADF y Databricks. Cada plugin se encarga ahora de la configuración y versionado de un conjunto de reglas de traducción de modelos. Estas reglas de traducción de modelos se aplican luego durante los procesos de extracción e ingesta de datos.
Cada plugin realiza las traducciones de los tipos de datos y puebla las reglas necesarias cuando se instala. La responsabilidad de rellenar esta tabla TypeTranslation también recae ahora en cada plugin específico, en lugar de estar centralizada en Sidra Core.
Esto significa que las diferentes asignaciones de tipos para cada plugin del conector están ahora completamente desvinculadas del proceso de liberación de versiones de Sidra Core y vinculadas únicamente al proceso de liberación del plugin correspondiente.
Como parte del robustecimiento operativo de la plataforma, hemos incorporado un conjunto de mejoras relacionadas con la creación y manejo de tablas Databricks en determinados escenarios. Este es el conjunto de cambios incluidos como parte de esta optimización:
<database>_<schema>_<table name>#,*, etc. Estos nombres se transforman en el carácter _ al pasar a Databricks. Esto significa que muchos de estos Atributos pueden acabar teniendo el mismo nombre. Para evitarlo, el cambio consiste en añadir un sufijo numérico a los nombres de las columnas en Databricks, por ejemplo, _1, _2, etc., para que no haya duplicación de nombres de columnas.La versión de ejecución de Databricks en Sidra ha sido actualizada a 8.3. Esto viene con interesantes actualizaciones y características, como Python 3.8, tiempos de inicio de clúster más rápidos, muchas mejoras de rendimiento y operadores como JSON en SQL, entre otros.
Hemos llevado a cabo una amplia revisión del marco y las capacidades de servicio del modelo ML de Sidra, para adaptarnos a los rápidos cambios del mercado y a la evolución técnica de los servicios clave de este módulo. Estas son las principales actualizaciones realizadas como parte de esta revisión:
Hemos implementado nuestra primera versión de una plantilla de pipelines de extracción e ingesta de datos de Oracle siguiendo las directrices de diseño de Sidra. Este proceso de ingesta de datos aún no se ha implementado como un plugin de tipo conector, pero está previsto para la próxima versión de Sidra. Las principales características de esta plantilla de Oracle son las siguientes:
Los pipelines de ingesta de datos para los sistemas de origen de las bases de datos (por ejemplo, SQL, DB2) incluían un parámetro de exclusión de tablas para configurar una lista de objetos a excluir por parte del pipeline de extracción de metadatos. Con esta versión de Sidra, hemos incorporado un mecanismo mejorado de selección de objetos, mediante el cual los usuarios pueden elegir una lista de objetos para incluir, o una lista de objetos para excluir. Por defecto, se configura el modo de inclusión con todos los objetos. Este cambio se ha llevado a los pipelines y plugins de bases de datos existentes: SQL Server, Azure SQL, DB2, además de los pipelines de Oracle. Internamente, los objetos a incluir o excluir se persisten en las tablas LoadRestrictionObject de la base de datos Sidra Core. Puedes ver la documentación de características sobre LoadRestrictions y About connectors.
Sidra incorpora ahora soporte para DB2 en el modelo de marco de conectores. Esto permite configurar un proceso de ingesta de datos desde sistemas de origen de bases de datos DB2 con solo seguir un asistente de configuración de pocos pasos. Esta versión del plugin viene con un mecanismo de carga incremental respaldado por Sidra.
Sidra incorpora una capacidad nativa que ejecuta diferentes runbooks operativos para automatizar la monitorización periódica de la salud de los servicios de la API, así como intentar el reinicio automático en caso de que se caigan. Esto se logra a través de la implementación de la cuenta de automatización de Azure.
Este lanzamiento viene con una nueva versión del pipeline de extracción de metadatos de SQL Server, que también se ha lanzado como una nueva versión del plugin de conectores de SQL Server. Esta versión permite configurar la extracción de metadatos de múltiples bases de datos dentro de un SQL Server a la vez, de modo que se vinculen lógicamente en Sidra con el mismo Proveedor.
Este cambio se ha realizado en el pipeline de extracción de metadatos del plugin de SQL Server. Ahora, en el plugin de SQL Server, si no se especifica una base de datos, se toma la base de datos por defecto como master, lo que obliga a recorrer toda la lista de bases de datos dentro del mismo SQL Server y extraer los metadatos de todas ellas.
Esto simplifica y agiliza enormemente el proceso de ingesta de datos, ya que ahora podemos configurar una fuente de datos donde hay un gran número de bases de datos diferentes en un servidor SQL con sólo unos pocos pasos.
La herramienta CLI de Sidra para instalaciones y actualizaciones ha sido revisada para asegurar que todos los comandos son idempotentes por defecto. Esto significa que los diferentes comandos pueden ser ejecutados varias veces sin necesidad de eliminar manualmente ningún dato de Azure. Esta mejora minimiza los problemas operativos que pueden ocurrir cuando hay algún problema inesperado al ejecutar los comandos. Más concretamente, el comando aadaplications se ha hecho idempotente, asegurando que todas las aplicaciones de AAD se eliminan automáticamente antes de volver a ejecutar el comando, sin necesidad de intervención manual.
Sidra incorpora ahora un Proveedor interno que contiene fuentes de datos pertinentes que se originan internamente en Sidra a partir de los módulos de generación de trazas y operativos.
La primera versión de este Proveedor interno de Sidra incluye la base de datos de registros en Sidra Core. La base de datos de logs almacena una copia de los Logs (trazas) de la plataforma, aplicando un conjunto de filtros. Hay varias tablas donde se encuentran los registros. Este proveedor mejora el rendimiento de la base de datos de registros, al trasladar las trazas más antiguas al lago de datos (desde donde se puede consultar y explorar a través de Databricks). Esto permite optimizar la base de datos de Logs reduciendo el periodo de retención en la base de datos a los últimos 30 días. El historial completo de Logs está disponible en las tablas de Databricks.
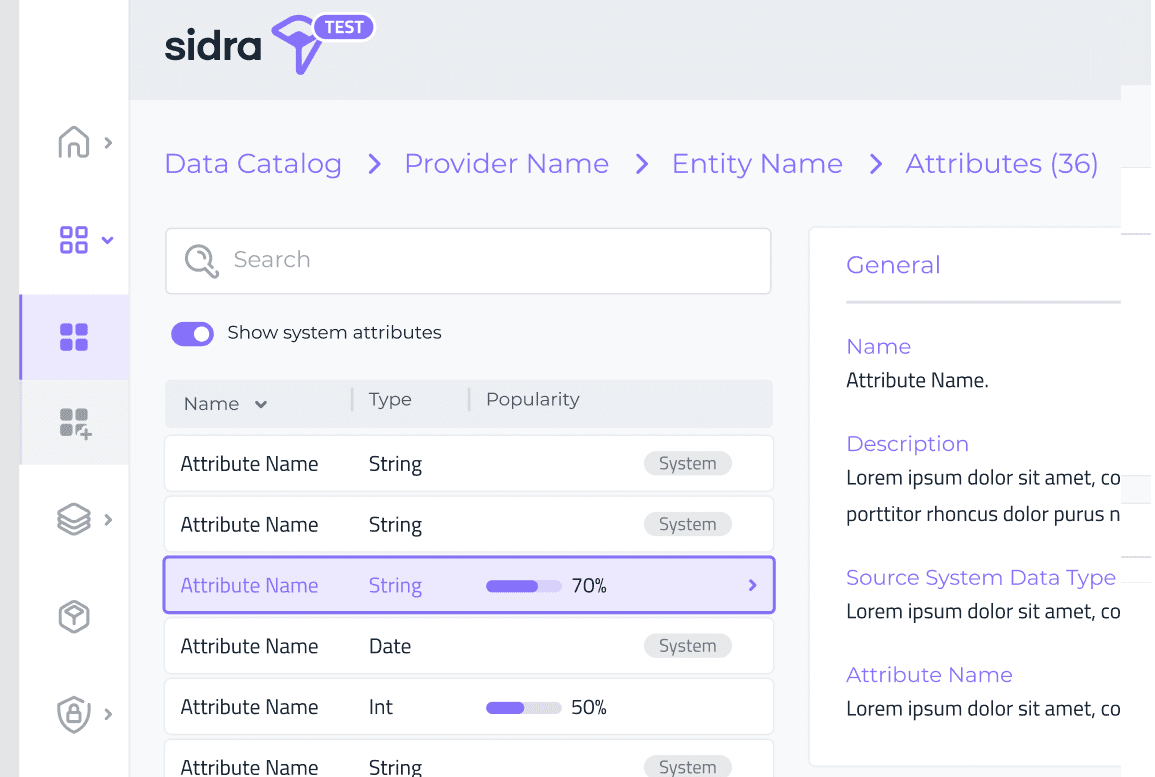
Sidra Data Catalog ahora incluye la capacidad de ver la popularidad de todos los Atributos en la lista de Atributos y en la página de detalles. Antes de esta función, sólo se mostraba la popularidad de los tres principales Atributos como muestra, en la página de detalles de la Entidad.
En Sidra estamos muy interesados en escuchar tu voz. Nos complace lanzar con este lanzamiento un nuevo portal de ideas de Sidra. Desde él podrás sugerir y votar ideas sobre la hoja de ruta de Sidra. El portal de ideas es también un gran lugar para ver lo que está por venir y echar un vistazo a las ideas más compartidas y votadas. ¡Agradecemos tus sugerencias y comentarios!
La API de Sidra incorpora ahora endpoints de la API para servir operaciones de creación, lectura, actualización y eliminación en la tabla EntityDeltaLoad.Esta tabla es una pieza clave en las tablas del esquema DataIngestion de Sidra. Esta tabla realiza un seguimiento completo de los datos necesarios para la gestión de las cargas incrementales desde los sistemas de origen, lo que es independiente de cualquier mecanismo de seguimiento de cambios soportado de forma nativa.
Consulta la documentación de Sidra sobre las tablas de DataIngestion para obtener más detalles sobre la estructura y el uso de esta tabla.
Acceso a la lista completa de problemas resueltos y cambios relevantes en Sidra 2021. R2, aquí.
Esta 2021.R2 ha sido una versión muy importante para Sidra, ya que ha añadido nuevos plugins de conectores que utilizan el modelo de plugins publicado anteriormente. Pero no solo eso: esta versión representa un paso importante para hacer que las pipelines existentes y la ingesta de datos sean lo suficientemente robustas como para manejar muchos escenarios nuevos.
Los fundamentos arquitectónicos del modelo de plugin de Aplicaciones Cliente, por lo tanto, la capacidad de desplegar Aplicaciones Cliente desde la web, también se han logrado como parte de esta versión de Sidra. Esto establece el camino hacia una forma ágil de empaquetar las Aplicaciones Cliente para que su despliegue sea muy sencillo de ejecutar.
Como parte de la próxima versión, estamos planeando entregar nuestro primer plugin de Aplicación Cliente propiedad de Sidra, con una Aplicación Cliente SQL básica como el primer plugin de su tipo. También, planeamos avanzar con el modelo de plugin para permitir más escenarios de configuración de actualización de plugins o actualización de versiones de plugins.
Los nuevos plugins se añadirán a la galería de conectores siguiendo un ciclo de lanzamiento que ya no tiene que estar ligado al ciclo de lanzamiento de Sidra Core.
Elena Canorea
Communications Lead
