
Elena Canorea
Communications Lead
Esta primera versión de 2021 viene con una actualización masiva de las capacidades de autoservicio de Sidra Data Platform, gracias al nuevo soporte para ciertas operaciones comunes en la interfaz de usuario web de Sidra. Esto ha tardado en lanzarse un poco más de lo que se esperaba inicialmente, pero estamos seguros de que te encantarán todas las nuevas capacidades!
La característica clave que se lanza como parte de esta versión es la compatibilidad con la configuración de conectores de entrada de datos desde la interfaz de usuario web, así como el lanzamiento de los dos primeros conectores nuevos. Esto ha sido posible gracias a una importante revisión arquitectónica, que logra envolver la lógica de cada conector en módulos independientes, denominados plugins.
Los conectores para Sidra representan una nueva forma de configurar fuentes de datos, a través de una interfaz fácil de usar incorporada en Sidra Web. También proporciona una forma para que Plain Concepts y nuestros socios desacoplen las conexiones de la fuente de datos de las diferentes versiones de Sidra, lo que permite que se publique un flujo continuo de nuevos conectores sin que los usuarios tengan que realizar una re-implementación de Sidra.
Es importante tener en cuenta que el trabajo arquitectónico realizado para habilitar esta función también ha sentado las bases de otra pista importante de mejoras en la configuración y las operaciones del autoservicio en Sidra: la creación y gestión de aplicaciones cliente desde la web, una emocionante nueva función que se planea para la próxima actualización.
Además, esta versión viene con características importantes en torno a la operatividad de la plataforma, tanto desde la web como desde la perspectiva de otras herramientas operativas.
La compatibilidad con la interfaz de usuario de conectores de datos es una característica importante cuyo exponente clave es visible en la interfaz de usuario web de Sidra. Los conectores Sidra se han concebido con el propósito de agregar más capacidades de autoservicio a Sidra. Este ha sido, y seguirá siendo, uno de los objetivos clave de la evolución de Sidra como producto.
Los conectores simplifican enormemente la configuración de la entrada de nuevas fuentes de datos en una unidad de almacenamiento de datos Sidra. Antes de los conectores de datos, la configuración de una nueva fuente de datos requería varias llamadas a la API (por ejemplo, para configurar metadatos, activadores, etc.) o, alternativamente, configurar los metadatos directamente en la base de datos principal de Sidra con scripts SQL. Si bien estos métodos seguirán estando disponibles para escenarios de configuración avanzada, con los nuevos conectores el proceso ahora se simplifica enormemente, ya que el enfoque de los conectores solo requiere que el usuario complete una serie de campos en un asistente paso a paso ( Datos> Conectores).
Al configurar y ejecutar un conector Sidra desde la web de Sidra, están involucrados varios pasos subyacentes. Por un lado, en Sidra se crean los metadatos necesarios y las estructuras de gobernanza de datos. Por otro lado, la infraestructura de integración de datos real (por ejemplo, tuberías) se crea, configura e implementa.
Un conector típico se configura en menos de cinco minutos. Justo después de que el usuario proporcione algunos detalles y confirme, se llevará a cabo toda la orquestación y las canalizaciones de entrada de datos para la nueva fuente de datos estarán en funcionamiento.
A partir de esta versión, la hoja de ruta de Sidra agregará gradualmente soporte para diferentes fuentes de datos a través de la interfaz de conectores.
La versión 2021.R1 viene con soporte listo para usar para dos conectores: Azure SQL Database y SQL Server. Estos se describen a continuación.
Los usuarios web de Sidra con privilegios de administrador pueden ver la galería con conectores disponibles en el menú Datos en Sidra Web:

A continuación, se lleva al usuario a través de una serie de pasos (modo asistente) para agregar la configuración necesaria para ese conector.
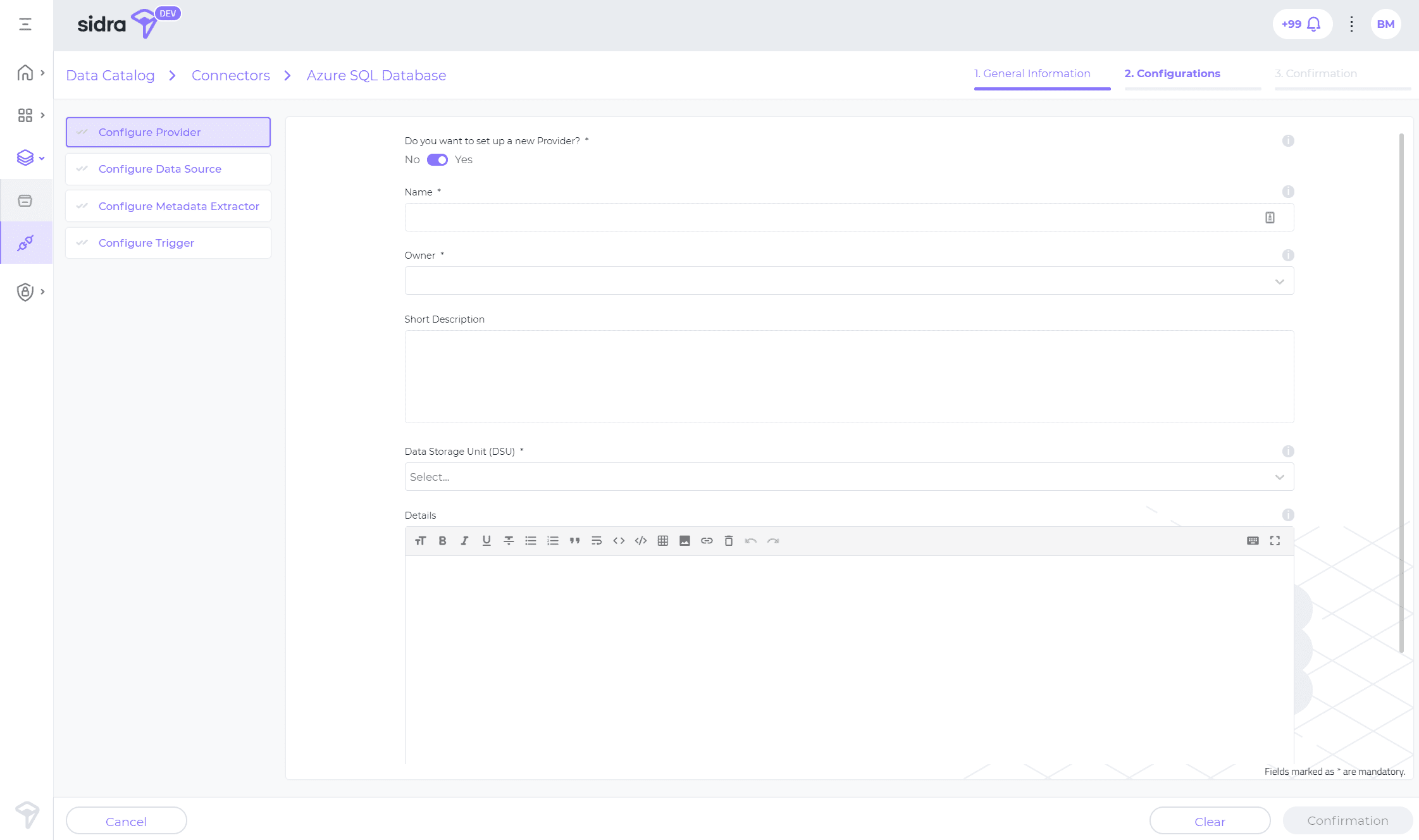 Antes de confirmar la creación de la infraestructura subyacente, existe la posibilidad de validar la conexión o exportar la configuración como un archivo JSON.
Antes de confirmar la creación de la infraestructura subyacente, existe la posibilidad de validar la conexión o exportar la configuración como un archivo JSON.
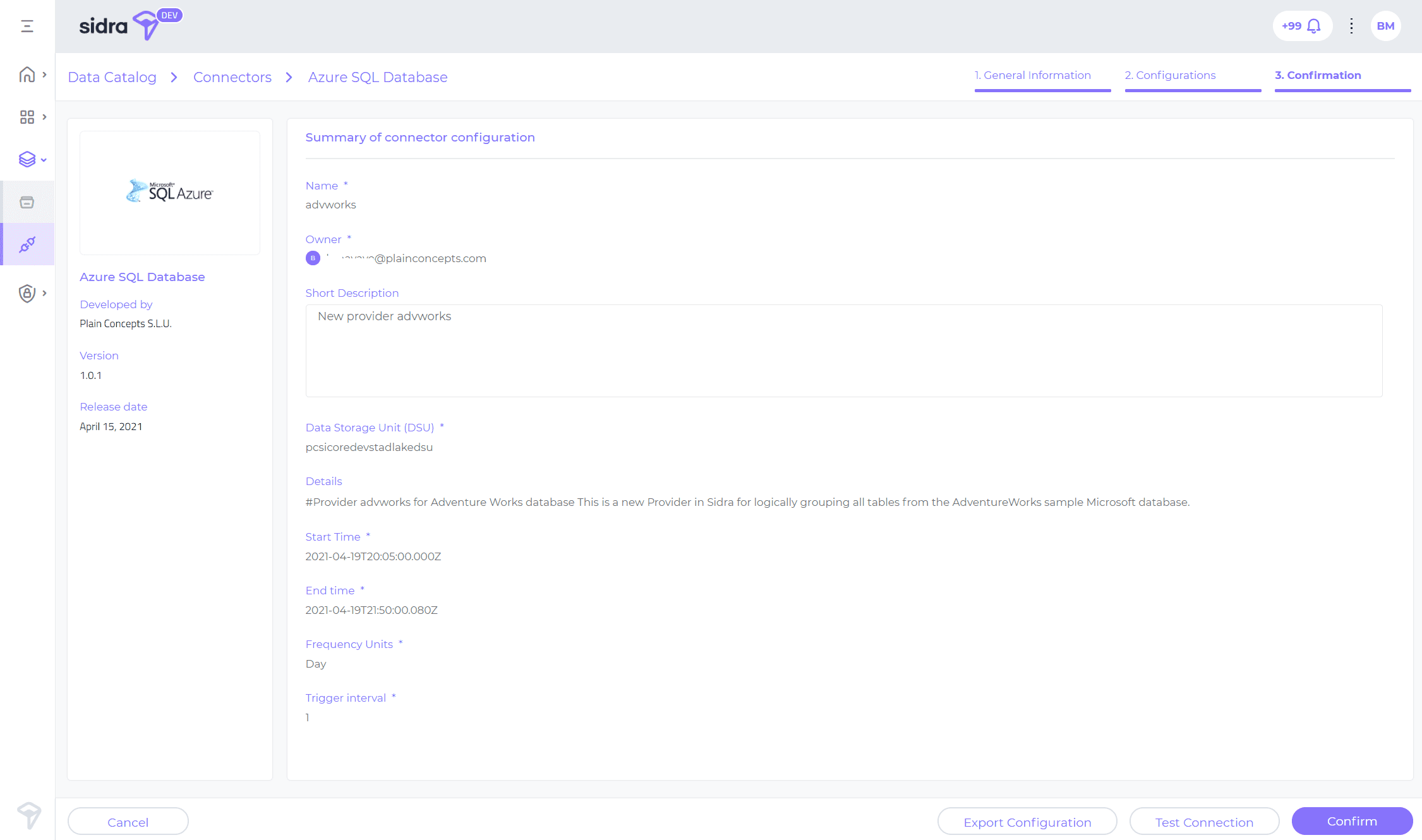 Conector SQL de Azure
Conector SQL de AzureEl conector de base de datos SQL de Azure para Sidra permite una integración perfecta con la base de datos de SQL Server como servicio más utilizada en Azure; un servicio de base de datos relacional, escalable e inteligente integrado en la nube. Azure SQL Database usa las capacidades más recientes de SQL Server y puede obtener más información al respecto en la documentación de Microsoft.
El conector de Sidra para la base de datos SQL de Azure extrae datos de cualquier tabla y vista en la base de datos de origen y los carga en la unidad de almacenamiento de datos especificada a intervalos regulares. Se basa en el modelo de metadatos de Sidra para asignar estructuras de datos de origen a Sidra como destino y utiliza Azure Data Factory como mecanismo de integración de datos subyacente dentro de Sidra.
Al configurar y ejecutar este conector, se requieren varios pasos subyacentes para lograr lo siguiente:
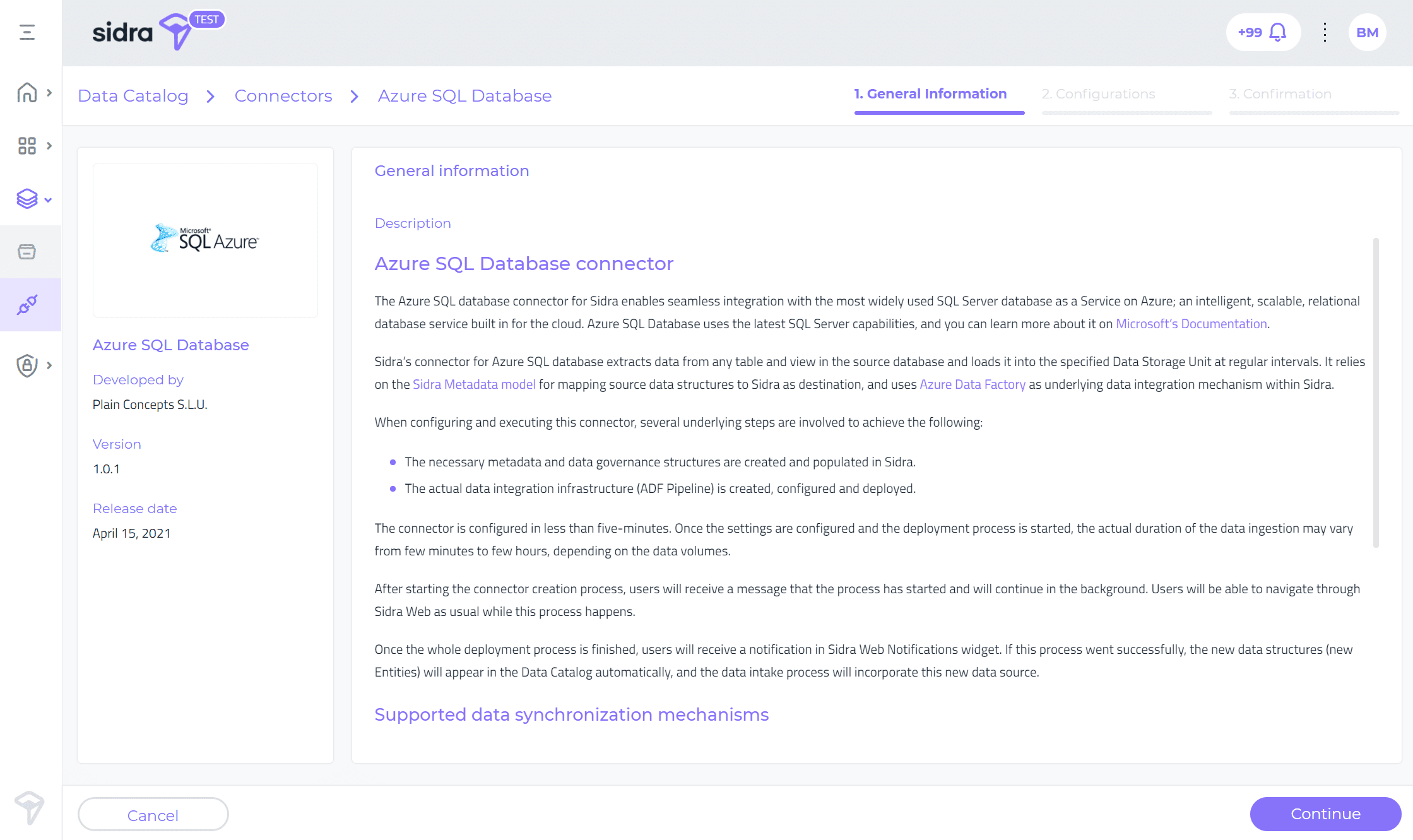 Después de iniciar el proceso de creación del conector, los usuarios recibirán un mensaje de que el proceso ha comenzado y continuará en segundo plano. Los usuarios podrán navegar a través de Sidra Web como de costumbre mientras se lleva a cabo este proceso.
Después de iniciar el proceso de creación del conector, los usuarios recibirán un mensaje de que el proceso ha comenzado y continuará en segundo plano. Los usuarios podrán navegar a través de Sidra Web como de costumbre mientras se lleva a cabo este proceso.
Una vez finalizado todo el proceso de implementación, los usuarios recibirán una notificación en el widget de notificaciones web de Sidra. Si este proceso ha tenido éxito, las nuevas estructuras de datos (nuevas entidades) aparecerán en el Catálogo de Datos automáticamente, y el proceso de entrada de datos incorporará esta nueva fuente de datos.
El conector de Azure SQL Database para Sidra admite diferentes modos de sincronización de datos, que también dependen de los mecanismos configurados en el sistema de origen o los metadatos de Sidra:
Para que la carga incremental funcione, debe haber un mecanismo definido para capturar actualizaciones en el sistema de origen. Para la sincronización de datos de carga incremental, se admiten dos tipos posibles de mecanismos:
Puedes ver más detalles sobre cómo funciona este conector y una guía de configuración en la documentación.
El conector de SQL Server para Sidra permite una integración perfecta con la poderosa base de datos relacional empresarial de Microsoft .
El conector de Sidra para SQL Server extrae datos de cualquier tabla y vista en la base de datos de origen y los carga en la unidad de almacenamiento de datos especificada a intervalos regulares. Se basa en el modelo de metadatos de Sidra para asignar estructuras de datos de origen a Sidra como destino y utiliza Azure Data Factory como mecanismo de integración de datos subyacente dentro de Sidra.
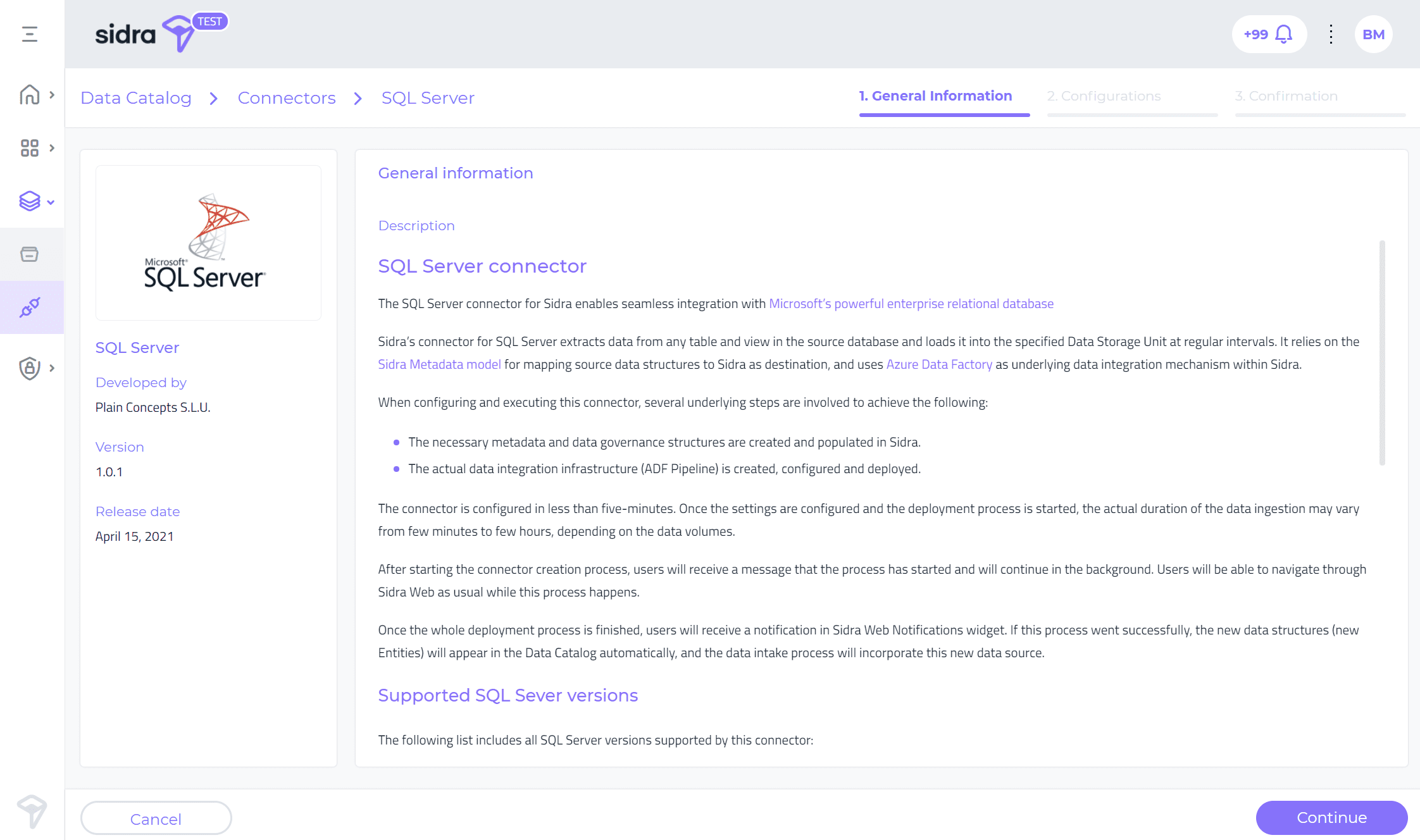 De manera similar al conector Azure SQL, al configurar y ejecutar este conector, se crean e implementan las infraestructuras de integración de datos y metadatos. El usuario recibirá una notificación una vez que finalice todo el proceso de implementación.
De manera similar al conector Azure SQL, al configurar y ejecutar este conector, se crean e implementan las infraestructuras de integración de datos y metadatos. El usuario recibirá una notificación una vez que finalice todo el proceso de implementación.
La siguiente lista incluye todas las versiones de SQL Server compatibles con este conector:
Nota: Se admiten todas las ediciones (Developer, Standard y Enterprise), pero algunas funciones del conector solo estarán disponibles si la edición de origen de SQL Server admite la función, como el requisito de la edición Enterprise para el seguimiento de cambios en las tablas.
El conector de SQL Server admite los mismos modos de sincronización de datos que Azure SQL Database.
Puedes ver más detalles sobre cómo funciona este conector y una guía de configuración en la documentación .
Como un esfuerzo continuo para facilitar el uso de la instalación y configuración de Sidra, la herramienta Sidra CLI ahora incluye la capacidad de exportar automáticamente datos sobre un Proveedor (incluidas sus Entidades y Atributos) desde un entorno (por ejemplo, dev), y para importar estos datos en otro entorno en la misma o diferente instalación.
El procedimiento solo necesita ejecutarse una vez por entorno de destino para replicar los metadatos configurados. Desde la perspectiva de la implementación, los datos se copian de forma transparente a una base de datos intermedia intermedia y las migraciones de datos se aplican hacia arriba o hacia abajo para establecer la misma migración en el destino.
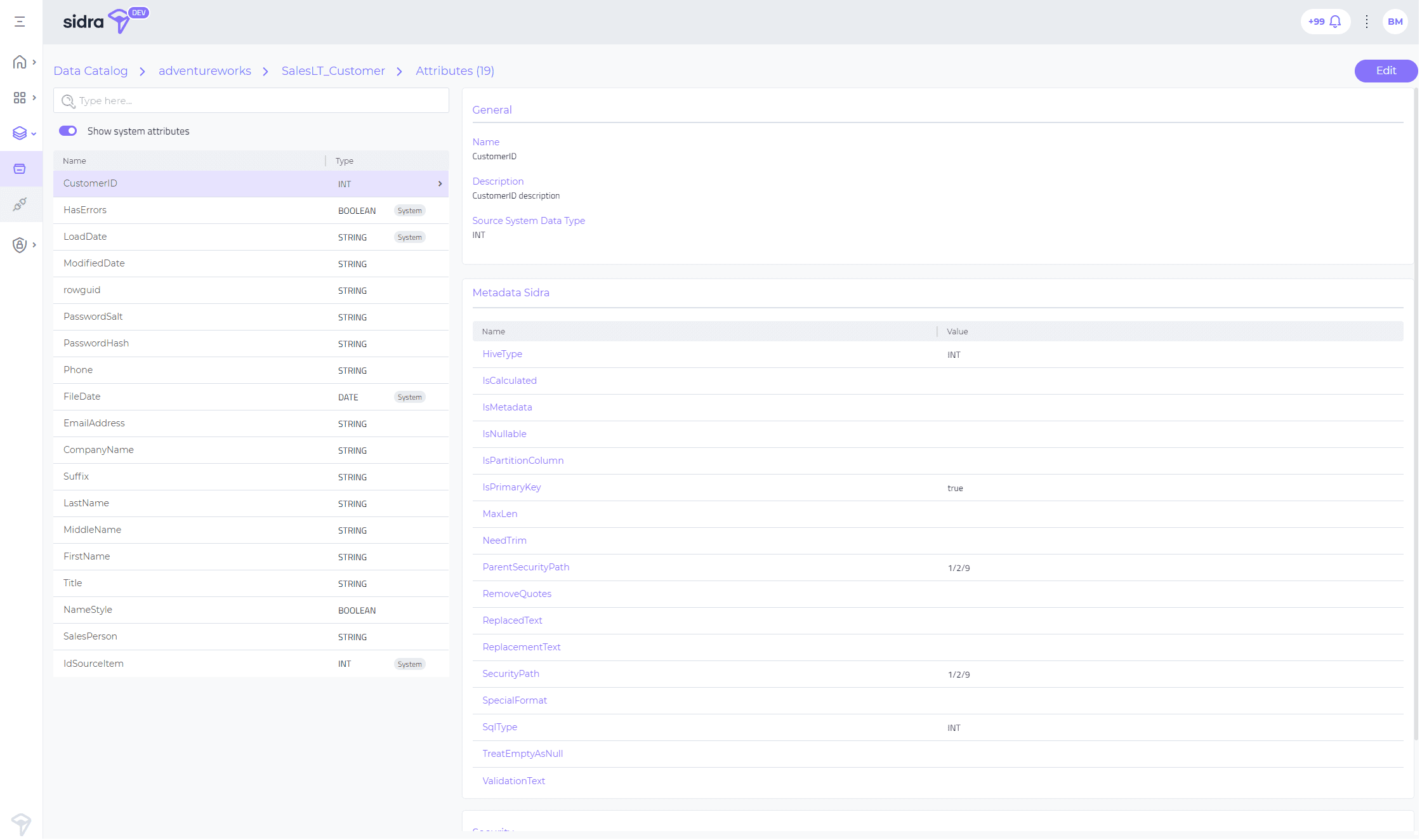
Esta característica completa la vista completa de los metadatos de Sidra de Sidra Web, al incluir una nueva vista detallada de Atributos para cada Entidad. Luego de seleccionar la entidad específica, el usuario puede optar por profundizar en la lista completa de Atributos (opción Ver Todos los Atributos), que están definidos en el sistema de metadatos para esa entidad. Esto incluye los Atributos originados en el sistema fuente, así como los Atributos del Sistema, aquellos Atributos técnicos creados por Sidra para transmitir información sobre cómo procesar una entidad específica.
Para cada Atributo, la vista Atributos permite ver todos los campos relevantes organizados en subsecciones: General, Metadatos y Seguridad.
 Telemetría mejorada
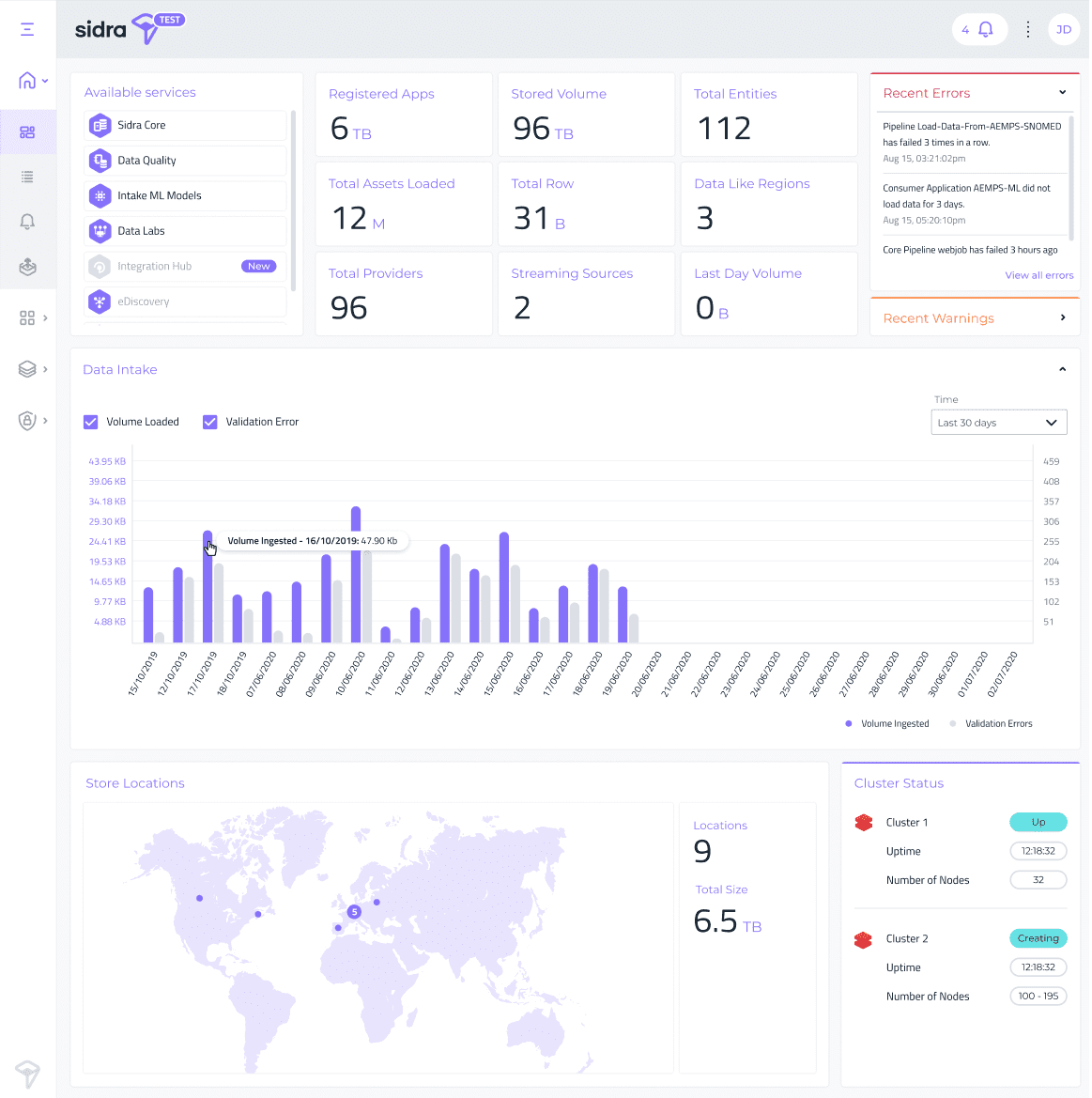
Telemetría mejoradaEsta característica permite que el equipo de soporte de Sidra tenga acceso a los datos operativos de las instalaciones de Sidra Core.
A partir de la versión 2020.R3, cada instalación de Sidra tenía acceso a un conjunto de informes operativos de Power BI que brindan información clave sobre las cifras de entrada de datos: volumen almacenado, ejecuciones de canalizaciones, etc. se beneficiará de una mejor supervisión y operatividad del equipo de Sidra. La información recopilada de esta telemetría permitirá reaccionar temprano en el tiempo sobre posibles anomalías y errores operativos, así como personalizar mejor el producto según las necesidades del cliente.
El trabajo de telemetría será transparente para el cliente y recopilará datos sobre métricas clave de admisión, errores, advertencias, notificaciones y métricas diarias del servicio.
Esta versión continúa basándose en las funcionalidades y mejoras de Sidra Web, en diferentes secciones:
 Rediseño de las notas de la versión:La página de notas de la versión en la web de Sidra ha sido rediseñada, con el objetivo de mostrar una línea de tiempo lineal de todas las versiones de Sidra.
Rediseño de las notas de la versión:La página de notas de la versión en la web de Sidra ha sido rediseñada, con el objetivo de mostrar una línea de tiempo lineal de todas las versiones de Sidra.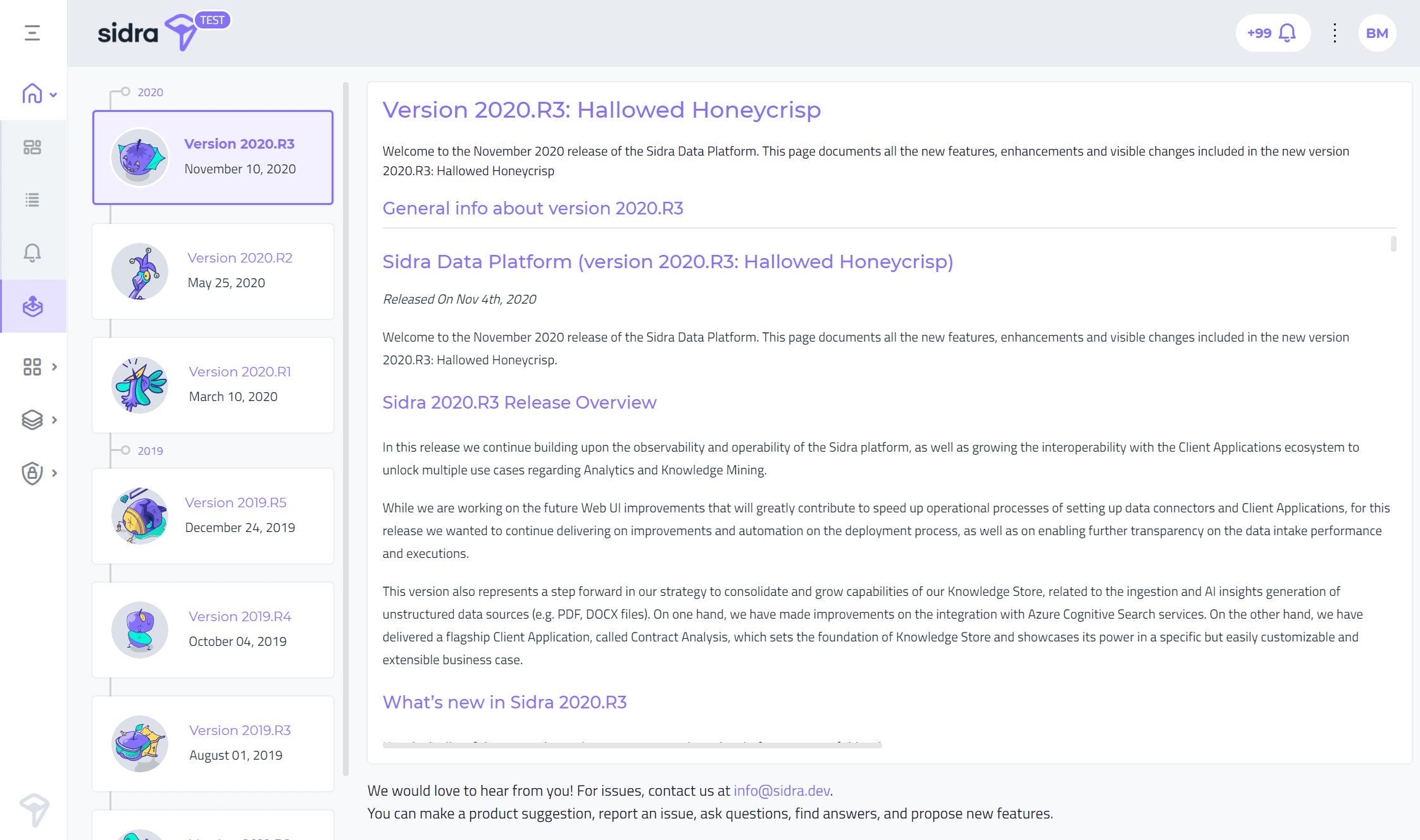 Visualización mejorada de Data Catalog para tipos de entidad:El catálogo de datos ahora incluye un soporte mejorado para mostrar el formato de una entidad. El formato de la entidad (por ejemplo, parquet, csv) ahora se muestra con un icono en la página de detalles de la entidad. La lista de entidades también incluye una columna con el formato de entidad.
Visualización mejorada de Data Catalog para tipos de entidad:El catálogo de datos ahora incluye un soporte mejorado para mostrar el formato de una entidad. El formato de la entidad (por ejemplo, parquet, csv) ahora se muestra con un icono en la página de detalles de la entidad. La lista de entidades también incluye una columna con el formato de entidad.Acceso a la lista completa de problemas resueltos y cambios relevantes en Sidra 2021. R1, aquí.
¡Nos encantaría saber de ti! Puedes hacer una sugerencia de producto, informar un problema, hacer preguntas, encontrar respuestas y proponer nuevas funciones a través de info@sidra.dev.
Elena Canorea
Communications Lead
