
Elena Canorea
Communications Lead
*Con la colaboración de Blanca Mayayo.
Data Lake vs. Data Warehouse vs. Data Mesh. Los especialistas en arquitectura de datos conocen estos tres conceptos. Data Lake y Data Warehouse atienden a diferentes formatos de almacenamiento, análisis y consultas de datos, mientras que Data Mesh engloba una serie de conceptos relacionados con la gestión de datos de manera descentralizada y a gran escala.
Según un estudio de Gartner de junio de 2020, un 57% de los directivos responsables de datos o analítica habían invertido en Data Warehouse y un 39% usado Data Lakes. De acuerdo con la consultora, los data hubs, Data Lakes y Data Warehouses «son todas ellas áreas importantes de inversión para que los líderes de datos y análisis respalden cargas de trabajo de datos cada vez más complejas, diversas y distribuidas».
Todas estas arquitecturas están ayudando a la democratización del uso de los datos en el seno de la empresa. Además, permiten administrarlos de forma más flexible que en el pasado.
Cada una de ellas tienen sus particularidades y sus ventajas frente a las otras. En este post las repasamos.
El Data Warehouse es una estructura nacida para ordenar las cantidades ingentes sin filtrar y de diversas fuentes. En este caso, los datos son solo estructurados, y se pueden analizar. Esta arquitectura permite que varias personas accedan al mismo tiempo con gran rendimiento.

Con el Data Warehouse, los datos, además de almacenarlos, se estructuran. Esta arquitectura es recomendable cuando se necesitan grandes cantidades de datos ya procesados para consultas. En ese caso, la productividad es mayor para determinados grupos de usuarios, como analistas de datos, o para integrarlos en aplicaciones analíticas (por ejemplo, de Business Intelligence).
El Data Warehouse destaca por procesar solo datos estructurados. Esto impide que se puedan usar datos no estructurados para aplicaciones de aprendizaje automático. Por otra parte, al ser mayoritariamente software con patente, puede resultar difícil vincularlo con herramientas externas de código abierto, si bien ya existen soluciones de integración a muchos sistemas.

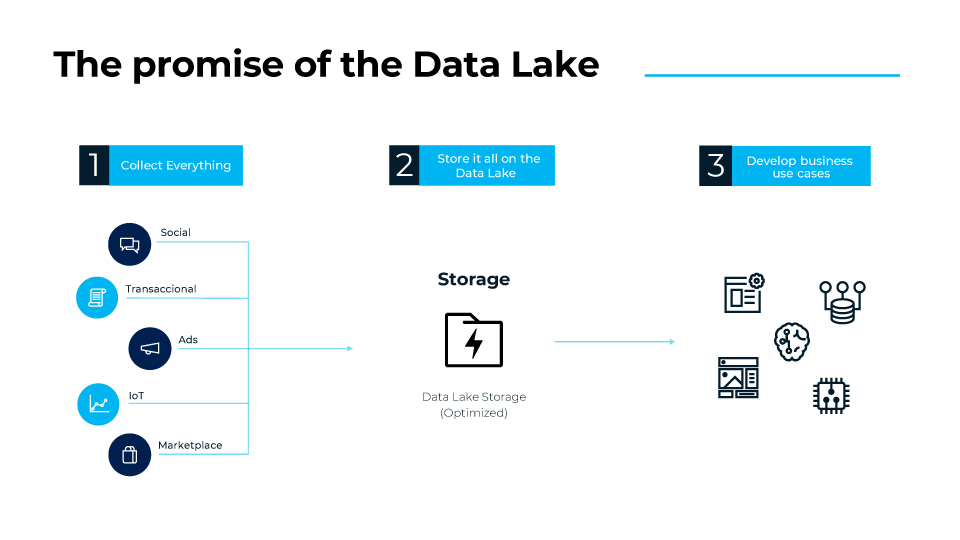
¿Qué es un Data Lake? Un Data Lake es un repositorio de datos donde, en una fase inicial, los datos se almacenan en crudo y sin un esquema unificado. De esta forma, los datos se disponibilizan para futuros usos. Si es necesario, capas añadidas en el Data Lake podrían procesar los datos y convertirlos y traducirlos a un esquema corporativo.
Así, los datos se guardan en bruto para usar en cualquier momento. Esto convierte al Data Lake en una estructura ideal cuando se sabe que van a ser reusados en el largo plazo y por diferentes sistemas y partes de la compañía.
Otras ventajas del Data Lake son:
Un concepto relacionado es el de Lakehouse, una combinación de Data Lake y Data Warehouse que combina los mejores elementos de ambas arquitecturas. Como hemos visto, es difícil integrar herramientas de código abierto en un Data Warehouse, así que unir estas dos filosofías es ideal para aprovechar al máximo lo que ambas ofrecen.
 Retos del Data Lake
Retos del Data LakeEntre los retos en los que hay que pensar antes de implantar Data Lake se encuentran:
El Data Mesh o malla de datos surgió como una nueva aproximación sociotécnica y organizacional de datos para responder a la complejidad, escala y necesidades crecientes en gestión de datos. En este caso, los sistemas y equipos del Data Mesh se descentralizan, interconectan y gestionan a gran escala. Una malla de datos podría beneficiarse de sistemas Data Lake o Data Warehouse, si se respeta la naturaleza de gestión granulada y descentralizada de los datos.
Así, un camino hacia el Data Mesh podría pasar por aprovechar estructuras de Data Warehouse o Data Lake existentes, pero cambiando su enfoque puramente centralizado y organizando los equipos y las capacidades de estas tecnologías en partes específicas de la arquitectura de datos, para que se puedan usar de una manera descentralizada. O sea, se puede construir sobre las experiencias previas usando Data Warehouse y Data Lake.
El Data Mesh es una estructura ideal para distribuir los datos entre los diferentes departamentos de una compañía. Es decir, van más allá del departamento de Data para que todos los empleados aprovechen las oportunidades de la información recopilada.
De hecho, el objetivo es que el análisis de los datos permita obtener métricas con las que tomar decisiones corporativas: encontrar nuevas oportunidades de negocio, corregir decisiones del pasado, etc.
En un artículo de LinkedIn, el vicepresidente de Products de Oracle, Jeffrey T. Pollock, explicó que el Data Mesh es ideal para aplicaciones como migraciones de aplicaciones a la nube; integración en tiempo real entre estas, IoT y analíticas, o el análisis de flujo de datos en movimiento.
Si quieres saber más sobre Data Mesh, nuestra compañera Blanca Mayayo impartió una charla sobre esta plataforma de datos y su vinculación con Sidra, una solución de productividad de gestión de datos que aporta un conjunto de herramientas y aceleradores desarrollados por Plain Concepts para ingestar, catalogar y administrar datos en Azure:
¿Quieres saber cuál es la arquitectura de datos idónea para tu negocio?
Como has visto, Data Warehouse, Data Lake y Data Mesh tienen planteamientos muy diferentes. Ahora solo queda que escojas el enfoque más adecuado.
Por nuestra parte, te ayudamos a escoger la mejor arquitectura de datos para tus objetivos empresariales. Te esperamos.

{
«@context»: «https://schema.org»,
«@type»: «FAQPage»,
«mainEntity»: [{
«@type»: «Question»,
«name»: «¿Data Lake: qué es?»,
«acceptedAnswer»: {
«@type»: «Answer»,
«text»: «¿Qué es un Data Lake? Un Data Lake es un repositorio de datos donde, en una fase inicial, los datos se almacenan en crudo y sin un esquema unificado. De esta forma, los datos se disponibilizan para futuros usos. Click en el enlace para saber más»
}
},{
«@type»: «Question»,
«name»: «¿Ventajas del Data Lake?»,
«acceptedAnswer»: {
«@type»: «Answer»,
«text»: «Así, los datos se guardan en bruto para usar en cualquier momento. Esto convierte al Data Lake en una estructura ideal cuando se sabe que van a ser reusados en el largo plazo y por diferentes sistemas y partes de la compañía.
Otras ventajas del Data Lake son: Click en el enlace para saber más»
}
},{
«@type»: «Question»,
«name»: «¿Data Warehouse: qué es?»,
«acceptedAnswer»: {
«@type»: «Answer»,
«text»: «El Data Warehouse es una estructura nacida para ordenar las cantidades ingentes sin filtrar y de diversas fuentes. En este caso, los datos son solo estructurados, y se pueden analizar. Esta arquitectura permite que varias personas accedan al mismo tiempo con gran rendimiento.»
}
},{
«@type»: «Question»,
«name»: «¿Beneficios de tener un Data Warehouse?»,
«acceptedAnswer»: {
«@type»: «Answer»,
«text»: «Con el Data Warehouse, los datos, además de almacenarlos, se estructuran. Esta arquitectura es recomendable cuando se necesitan grandes cantidades de datos ya procesados para consultas. En ese caso, la productividad es mayor para determinados grupos de usuarios, como analistas de datos, o para integrarlos en aplicaciones analíticas (por ejemplo, de Business Intelligence).»
}
},{
«@type»: «Question»,
«name»: «¿Data Mesh: qué es?»,
«acceptedAnswer»: {
«@type»: «Answer»,
«text»: «El Data Mesh o malla de datos surgió como una nueva aproximación sociotécnica y organizacional de datos para responder a la complejidad, escala y necesidades crecientes en gestión de datos. En este caso, los sistemas y equipos del Data Mesh se descentralizan, interconectan y gestionan a gran escala. Una malla de datos podría beneficiarse de sistemas Data Lake o Data Warehouse, si se respeta la naturaleza de gestión granulada y descentralizada de los datos.Click en el enlace para saber más»
}
},{
«@type»: «Question»,
«name»: «¿Ventajas del Data Mesh?»,
«acceptedAnswer»: {
«@type»: «Answer»,
«text»: «El Data Mesh es una estructura ideal para distribuir los datos entre los diferentes departamentos de una compañía. Es decir, van más allá del departamento de Data para que todos los empleados aprovechen las oportunidades de la información recopilada.»
}
}]
}
Elena Canorea
Communications Lead
