
Elena Canorea
Communications Lead
Intro
En un panorama liderado por los datos y donde las empresas se suelen sentir sobrepasadas por la cantidad de los mismos que manejan, nos encontramos con una situación empresarial que necesita un cambio urgente.
Los datos sin procesar y desorganizados suelen almacenarse en sistemas de almacenamiento, pero que por sí solos no tienen el contexto ni el significado adecuados para brindar información significativa a los analistas, científicos de datos o tomadores de decisiones comerciales. En este punto, analizamos el papel que tienen herramientas como Azure Data Factory a través de una guía para que te conviertas en un experto y puedas sacar todo el partido a tus datos.
Azure Data Factory es una solución de datos en la nube que permite ingerir, preparar y transformar los datos a gran escala. Facilita su uso para una amplia variedad de casos de uso, como ingeniería de datos, migración de los paquetes locales a Azure, integración de datos operativos, análisis, ingesta de datos en almacenes, etc.
Los macrodatos requieren de un servicio que pueda organizar y poner en funcionamiento procesos para refinar estos enormes depósitos de datos sin procesar y convertirlos en información empresarial procesable. Aquí es donde entra Azure Data Factory, pues está diseñado para estos complejos proyectos híbridos de extract-transform-load (ETL), extract-load-transform (ELT) e integración de datos.
Las características principales de esta solución son:
ADF cuenta con componentes clave que trabajan juntos para proporcionar la plataforma en la que se pueden componen flujos de trabajo basados en datos con pasos para mover y transformar datos:
Data Factory contiene una serie de sistemas interconectados que proporcionan una plataforma completa de extremo a extremo para ingenieros de datos. En esta imagen se puede ver de forma detallada la arquitectura completa:
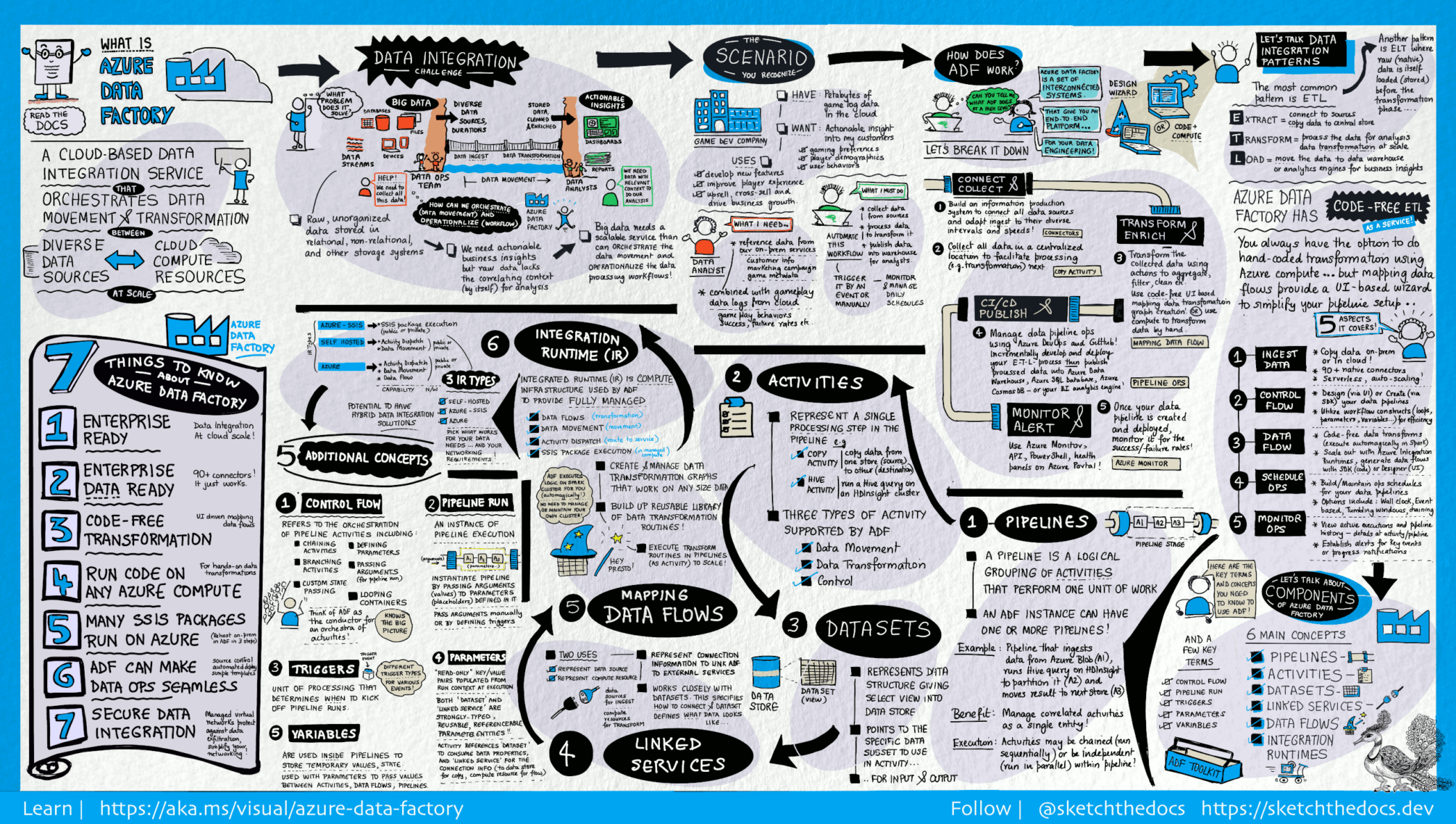
El primer paso para crear un sistema de producción de información es conectarse a todas las fuentes de datos y procesamiento necesarias, como SaaS, bases de datos, recursos compartidos de archivos y servicios web FTP. Después de trasladan los datos, según sea necesario, a una ubicación centralizada para su posterior procesamiento.
Sin Data Factory, las empresas deben crear componentes de movimiento de datos personalizados o escribir servicios personalizados para integrar estas fuentes de datos y su procesamiento. Integrar y mantener estos sistemas es costoso y difícil, además de carecer de la supervisión, alertas y controles empresariales que puede ofrecer un servicio administrado como este.
Con Data Factory, se puede usar la actividad de copia en una canalización de datos para moverlos desde almacenes de datos locales y en la nube a un almacén centralizado cloud para su posterior análisis.
Una vez que los datos se encuentran en un almacén de datos centralizado cloud, se pueden procesar o transformar los datos recopilados mediante flujos de datos de mapeo de ADF. Estos permiten crear y mantener gráficos de transformación de datos que se ejecutan en Spark sin necesidad de comprender los clústeres de Spark ni su programación.
Además, si se quieren codificar transformaciones de forma manual, el servicio de data admite actividades externas para ejecutar sus transformaciones en servicios de cómputo como HDInsight Hadoop, Spark, Data Lake Analytics y Machine Learning.
ADF también ofrece Soporte para CI/CD de sus canales de datos mediante Azure DevOps y GitHub. Esto permite desarrollar y entregar de manera incremental los procesos ETL antes de publicar el producto terminado.
Una vez que los datos sin procesar se hayan refinado en un formato listo para su uso comercial, se pueden cargar en Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB o cualquier motor de análisis al que tus usuarios comerciales puedan apuntar desde sus herramientas de inteligencia empresarial.
Una vez que se haya creado e implementado correctamente la canalización de integración de datos, se podrá obtener valor comercial a partir de datos refinados, monitorear las actividades y canalizaciones programadas para conocer las tasas de éxito y fracaso.
Analizando Azure Data Factory y Databricks, a pesar de ser de servicios de data mas populares del mercado, encontramos diferencias:
ADF está diseñado para la integración y orquestación de datos, destacando por mover datos entre varias fuentes, transformarlos y cargarlos en una ubicación centralizada para su posterior análisis. Por ello es ideal para escenarios en los que se necesita automatizar y administrar flujos de trabajo de datos en varios entornos.
Por su parte, Databricks se centra en el procesamiento de datos, el análisis y el ML. Es la plataforma de referencia para las compañías que buscan realizar análisis de datos a gran escala, desarrollar modelos de ML y colaborar en proyectos de ciencia de datos.
ADF ofrece capacidades de transformación de datos a través de su función Data Flow, que permite a los usuarios realizar varias transformaciones directamente dentro de la canalización. Aunque son potentes, estas transformaciones suelen ser más adecuadas para los procesos ETL y pueden no ser tan extensas o flexibles como las que ofrece Databricks.
Esta última ofrece capacidades avanzadas de transformación de datos. Los usuarios pueden aprovechar toda la potencia de Spark para realizar transformaciones, agregaciones y tareas de procesamiento de datos complejas, lo que lo hace muy atractiva en la manipulación y cálculo de datos.
Ambas se integran con otros servicios de Azure, pero con enfoques diferentes. ADF está diseñado para ETL y orquestación, lo que hace que sea la mejor herramienta para administrar flujos de trabajo de datos que involucran múltiples servicios de Azure.
Databricks, al estar más centrado en el análisis avanzado y la IA, se integra mejor con servicios como Delta Lake para el almacenamiento de datos y Azure Machine Learning para la implementación de modelos.
La interfaz de arrastrar y soltar de Azure Data Factory hace que sea sencillo su uso, incluso para perfiles con pocos conocimientos técnicos.
Sin embargo, Databricks requiere de un nivel mayor de competencia técnica, lo que lo hace más adecuado para ingenieros y científicos de datos.
Las dos son altamente escalables, pero cada una destaca en áreas diferentes. ADF está diseñado para manejar tareas de migración e integración de datos a gran escala, lo que la hace perfecta para orquestar flujos de trabajo ETL complejos.
Databricks ofrece un rendimiento superior para el procesamiento y análisis de grandes volúmenes de datos, lo que le hace la mejor opción para escenarios que requieren escalabilidad y computación de alto rendimiento.
La asignación de flujos de datos es una transformación de datos diseñada visualmente en Azure Data Factory. Permiten desarrollar lógica de transformación sin necesidad de escribir código, los cuales se ejecutan como actividades de canalizaciones que usan clústeres de Apache Spark con escalabilidad horizontal.
Las actividades de flujo de datos pueden ponerse en marcha mediante capacidades de programación, control, flujo y supervisión de ADF.
Proporcionan una experiencia completamente visual que no requiere programación, pues ADF controla toda la traducción de código, la optimización de rutas de acceso y la ejecución de los trabajos de flujo de datos.
Se crean desde el panel Factory Resources como canalizaciones y conjuntos de datos de forma sencilla y siguiendo el lienzo de flujo de datos.
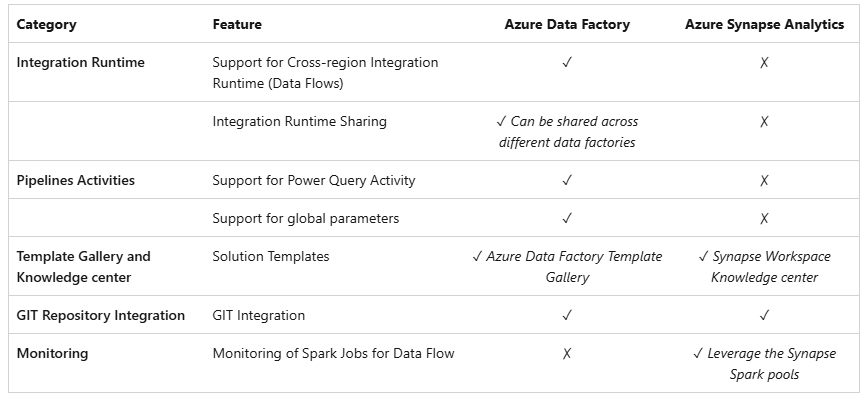
Ambas herramientas tienen mucha relación entre sí, pues, en Azure Synapse Analytics, las funcionalidades de integración de datos, como los flujos de datos y las canalizaciones de Synapse, se basan en las de Azure Data Factory.
Si comparamos sus capacidades principales, encontramos lo siguiente:
Los usuarios se han acostumbrado a datos interactivos, disponibles bajo demanda y prácticamente ilimitados. Todo ello hace que se exija una mejor experiencia de usuario, y el análisis de datos en tiempo real es una rama empresarial clave, que revoluciona los procesos de toma de decisiones y da forma dinámica a las estrategias de una organización.
Ante un entorno empresarial tan cambiante, la capacidad de analizar datos al instante se ha convertido en una necesidad y, gracias a él, las empresas consiguen la capacidad de monitorear eventos en tiempo real.
Gracias a eso podrás reaccionar rápidamente a los cambios y resolver problemas potenciales. Y en Plain Concepts te ayudamos a sacarle el máximo partido.
En Plain Concepts te proponemos una estrategia de data en la que puedas obtener valor y sacar el máximo rendimiento de tus datos.
Te ayudamos a descubrir cómo obtener valor de tus datos, a controlar y analizar todas tus fuentes de datos y utilizar los datos para tomar decisiones inteligentes y acelerar tu negocio:
Además, te ofrecemos un Framework de adopción de Microsoft Fabric con el que evaluaremos las soluciones tecnológicas y de negocio, haremos un roadmap claro para la estrategia del dato, visualizamos los casos de uso que marquen la diferencia en tu compañía, tenemos en cuenta el dimensionamiento de equipos, tiempos y costes, estudiamos la compatibilidad con plataformas de datos existentes y migramos soluciones de Power BI, Synapse y Datawarehouse a Fabric.
¡No te pierdas el webinar “Microsoft Fabric: Revolucionando el panorama de Datos e IA”, una charla en la que se exploran cómo los desarrolladores están aprovechando las aplicaciones y servicios de GenAI y LLMs en la era moderna!

Elena Canorea
Communications Lead
