
Artículo coescrito por Estefanía Guzmán y José Ángel Quevedo.
A diferencia del proceso ETL, que requiere que las transformaciones de datos se realicen antes del proceso de carga al sistema destino, el proceso ELT sigue una estrategia diferente. En lugar de mover los datos a un entorno intermedio para la transformación, el ELT carga los datos sin procesar, directamente en el sistema de almacenamiento, y realiza las transformaciones de manera posterior.
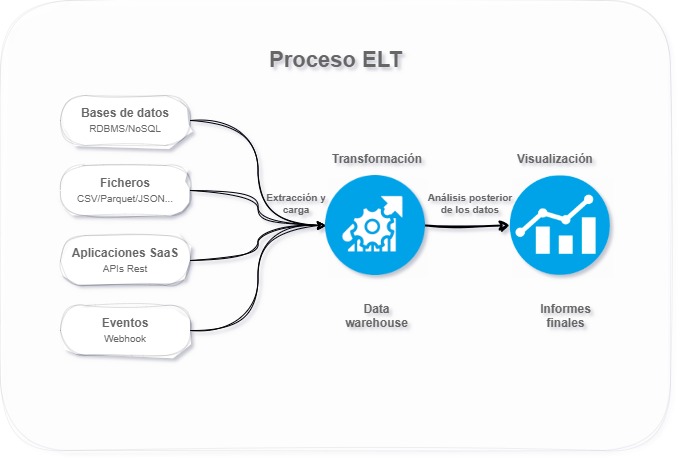
Mediante el uso del proceso ELT de flujo de datos, se lleva a cabo la limpieza, el enriquecimiento y la transformación de los datos directamente en nuestro sistema de almacenamiento. Los datos brutos se almacenan de forma permanente en dicho sistema, lo que permite realizar múltiples transformaciones en cualquier momento.
Los sistemas de almacenamiento de datos en la nube, como Snowflake, Amazon Redshift, Google BigQuery, Azure Data Lake, Azure Synapse, entre otros, cuentan con la infraestructura digital necesaria, tanto en términos de almacenamiento como de capacidad de procesamiento, para manejar grandes volúmenes de datos.
Aunque el pipeline de datos del ELT no se utiliza de manera universal, su popularidad está aumentando a medida que las empresas migran sus infraestructuras a entornos en la nube.
ETL vs. ELT: ¿En qué se diferencian los procesos ETL y ELT?
Existen dos aspectos principales que diferencian los procesos ETL y ELT: el primero es el lugar donde se lleva a cabo la transformación de los datos, mientras que el segundo está relacionado con la forma en que los datos son retenidos en los sistemas de almacenamiento.
El ETL transforma los datos en un servidor de procesamiento separado, mientras que el ELT transforma los datos dentro del propio almacén de datos.
Es decir, el ETL no transfiere datos al almacén sin antes procesarlos, mientras que ELT sí envía datos sin procesar directamente al almacén.
En el caso de ETL, el proceso de ingesta de datos se ralentiza al transformar los datos en un servidor separado antes del proceso de carga.
Por el contrario, en el proceso de ELT, se ofrece una ingesta de datos más rápida, porque los datos no se envían a un servidor secundario para su reestructuración. De hecho, con ELT, los datos se pueden cargar y transformar simultáneamente.
La retención de datos sin procesar del ELT crea un archivo histórico ideal para generar inteligencia empresarial. A medida que cambian los objetivos y las estrategias, los equipos de BI pueden volver a consultar los datos sin procesar para desarrollar nuevas transformaciones utilizando conjuntos de datos completos. El ETL, por otro lado, no genera conjuntos completos de datos sin procesar que se puedan consultar nuevamente: solo almacena datos ya transformados.
Estos factores hacen que el ELT sea más flexible, eficiente y escalable, especialmente para la ingesta de grandes cantidades de datos, el procesamiento de conjuntos que contienen datos estructurados y no estructurados y el desarrollo de diversas inteligencias empresariales.
La forma en que se procesan los datos no estructurados es crucial. En este momento, el ELT es la mejor opción, ya que proporciona un procesamiento superior de datos semiestructurados y no estructurados en comparación con ETL, que se utiliza típicamente para datos estructurados.
La mayoría de los datos son no estructurados (imágenes, vídeos, archivos PDF, documentos de PowerPoint, etc.), por eso este tipo de datos sigue siendo más difícil de acceder y procesar. En el futuro, la industria se centrará en eliminar las dificultades y mejorar la interpretación de estos datos no estructurados, y el ELT tendrá un papel importante en ello.
Sin embargo, el ETL es ideal para transformaciones intensivas en cómputo, sistemas con arquitecturas heredadas o flujos de trabajo de datos que requieren manipulación antes de ingresar a un sistema de destino, como la eliminación de información de identificación personal (PII).
La canalización de datos del ETL y del ELT incluye la limpieza y el filtrado, que son una parte clave del proceso de transformación de datos. Y debido a que el método ETL completa la transformación antes de cargar los datos en el servidor, es mejor para cumplir con los estándares de privacidad y seguridad ante la posibilidad de transferencia de datos sensibles.
Comparación de ETL vs. ELT
| Categoría | ETL | ELT |
| Definición | Los datos se extraen de un sistema fuente, se transforman en un servidor de procesamiento secundario y se cargan en un sistema de destino. | Los datos se extraen de un sistema fuente, se cargan en un sistema de destino y se transforman dentro del sistema de destino. |
| Extracción | Los datos en bruto se extraen mediante conectores API. | Los datos en bruto se extraen mediante conectores API. |
| Transformación | Los datos en bruto se transforman en un servidor de procesamiento. | Los datos en bruto se transforman dentro del sistema de destino. |
| Carga | Los datos transformados se cargan en un sistema de destino. | Los datos en bruto se cargan directamente en el sistema de destino. |
| Velocidad | ETL es un proceso que requiere mucho tiempo; los datos se transforman antes de cargarlos en un sistema de destino. | ELT es más rápido en comparación; los datos se cargan directamente en un sistema de destino y se transforman en paralelo. |
| Transformaciones basadas en código | Se realizan en un servidor secundario. Lo mejor para transformaciones intensivas en cómputo y prelimpieza. | Transformaciones realizadas en la base de datos; carga y transformaciones simultáneas; velocidad y eficiencia. |
| Privacidad | La transformación previa a la carga puede eliminar la PII (ayuda para HIPPA). | La carga directa de datos requiere más salvaguardas de privacidad. |
| Mantenimiento | El servidor de procesamiento secundario aumenta la carga de mantenimiento. | Al hacer uso de menos sistemas se reduce la carga del mantenimiento. |
| Flujo | Los datos se transforman antes de ingresar al sistema de destino; por lo tanto, no se pueden volver a consultar los datos en bruto. | Los datos en bruto se cargan directamente en el sistema de destino y se pueden volver a consultar indefinidamente. |
| Volumen de datos | Ideal para conjuntos de datos pequeños con requisitos de transformación complicados. | Ideal para conjuntos de datos grandes que requieren velocidad y eficiencia. |
Conclusión
Los almacenes de datos en la nube han dado lugar a una nueva frontera en la integración de datos. Elegir entre procesos de ETL y ELT depende de las necesidades del equipo y del proyecto.
Sin embargo, para ambos casos, el objetivo es claro: preparar datos para el análisis y usarlos para una toma de decisiones. La forma más sencilla de resolver el dilema ETL frente a ELT y comprender sus diferencias es entender la T en ambos enfoques. El factor crítico que diferencia a los dos es cuándo y dónde tiene lugar la ejecución de la transformación.
Implementar un proceso ELT es más difícil en comparación con ETL. Sin embargo, ahora las empresas prefieren ELT a ETL debido a un rendimiento más rápido, versatilidad y escalabilidad.
En contraposición, los pipelines de datos de ETL crean un proceso más seguro para manejar datos confidenciales y cumplir las normas de conformidad.
Sea cual sea la opción elegida, los equipos de datos de todo el espectro están activando sus estrategias de integración aprovechando una plataforma de integración de datos. Nosotros te podemos ayudar a que cuentes con una de ellas.

Categorías
Post Relacionados
3min. read
Plain Concepts, reconocido como Microsoft Fabric Featured Partner
Plain Concepts ha sido reconocido como Microsoft Fabric Featured Partner por su experiencia en el diseño e implementación de plataformas de datos modernas, escalables y preparadas para impulsar la inteligencia artificial.
4min. read
CompactifAI en n8n: IA eficiente integrada en workflows reales
Plain Concepts Research y Multiverse lanzan un community node open source que integra los modelos de IA comprimidos de CompactifAI en los workflows de n8n.
19min. read
¡Evergine 2026 ya está aquí!
Evergine 2026 ya está disponible, con visualización geoespacial a escala global, renderizado con IA, soporte para Avalonia, .NET 10, mejoras en Gaussian Splatting y grandes optimizaciones de rendimiento para aplicaciones 3D industriales en tiempo real.