
Ya hemos hablado de las características del Machine Learning Operations o MLops. Hoy es el turno de avanzar en sus características técnicas para aprovechar sus posibilidades. En concreto, vamos a explicar los ciclos MLOps y su utilidad en una industria cada vez más interesada en los modelos de machine learning.
Desde las características de las plataformas MLOps hasta labores como registro e implementación de modelos, te explicamos todo lo que necesitas saber.
Evaluación MLOps | Plataformas
MLOps utiliza tres tipos de artefactos principales: datos, modelo y código. Cada uno de ellos tiene diferentes ciclos de desarrollo y desafíos; por ejemplo, el ciclo de datos suele ser más rápido que el ciclo de código. Estas diferencias y combinaciones explican la complejidad de MLOps y el tamaño del ecosistema de herramientas para trabajar con ello.
En este sentido, una plataforma MLOps abstrae la capa de infraestructura que se ejecuta debajo y que ha sido creada para reducir los tiempos operativos en la construcción y despliegue de modelos, así como para mantener la estabilidad y reproducibilidad de las predicciones.
Hasta el momento, podemos considerar que no existe una plataforma MLOps que soporte el desarrollo de productos de extremo a extremo y que la comunidad haya aceptado ampliamente. Esto nos deja la opción de usar componentes de una plataforma que sean útiles (vendor lock-in) y/o integrar un flujo de trabajo de ML usando diferentes frameworks independientes y más especializados (aumento de coste y tiempo de entrega).
Características de una plataforma MLOps
- Despliegues automatizados, más fáciles y rápidos.
- Mantiene un registro de los experimentos. En su interfaz es posible comparar los sucesivos resultados del desarrollo del modelo.
- Capacidad para reproducir lo que han hecho otros miembros del equipo. Esto es especialmente desafiante si desea que otro científico de datos use su código o si desea ejecutar el mismo código en una escala en otra plataforma (por ejemplo, en la nube). Así, existen diferentes herramientas para cubrir este punto.
- Forma estándar de empaquetar e implementar modelos. Cada equipo de ciencia de datos acuerda su propio enfoque para cada biblioteca de machine learning que utiliza, y a menudo se pierde el vínculo entre un modelo y el código y los parámetros que se producen. Es por eso por lo que se requiere un estándar, y todos los miembros del equipo deben seguir las mismas prácticas.
- Almacén central para la gestión de modelos, sus versiones y transiciones de escenario. Un equipo de ciencia de datos crea muchos modelos. En ausencia de un lugar común para colaborar y administrar el ciclo de vida del modelo, los equipos de ciencia de datos enfrentan desafíos en la forma en que administran las etapas de los modelos: desde el desarrollo hasta la puesta en producción con sus respectivas versiones, anotaciones e historial. Para facilitar el trabajo a los equipos y aislar errores, se automatizan todo este proceso.
- Monitorización. Después de implementar modelos en producción es necesario evaluar su estado y cómo evolucionan en el futuro. Esa es la razón principal por la que necesitamos algo para monitorear estos comportamientos.
En las siguientes secciones, revisaremos todas las partes involucradas en el uso de una plataforma MLOps para el correcto seguimiento, evaluación, implementación y monitorización de los modelos.
Tracking Server
Los servidores de seguimiento del entrenamiento permiten el registro de cualquier parámetro asociado con el modelado. Por ejemplo, cuando queremos guardar cualquier tipo de hiperparámetro utilizado en el entrenamiento del modelo.
En otras ocasiones, podemos almacenar la métrica actual del modelo. Por ejemplo, en el caso de un modelo de regresión podemos calcular el RMSE (Root Mean Square); o, en el caso de un modelo de clasificación, podemos calcular el F1-score y almacenarlo junto con el modelo. De esta forma, podemos recuperar esta información como metadatos asociados a este.
Azure ML y MLflow
Azure ML permite examinar los artefactos almacenados en el Model Store a través de la aplicación web y mediante programación con la API de Python.
[vc_column][vc_single_image image=»110149″ img_size=»large» alignment=»center» onclick=»link_image»][/vc_column][/vc_row]
Seguimiento de experimentos con la interfaz de usuario y la API de Azure ML
Por otro lado, MLflow permite el acceso a los artefactos almacenados, parámetros y métricas utilizando el portal web y a través de la API de Python. En ambos casos, se pueden establecer filtros para experimentos, etiquetas, métricas y parámetros del modelo.
[vc_row][vc_column][vc_single_image image=»109083″ img_size=»large» alignment=»center» onclick=»link_image»][/vc_column][/vc_row]
Seguimiento de experimentos en MLflow
Según el framework utilizado para realizar el seguimiento de sus experimentos, existe una forma sencilla de realizarlo: el registro automático (autolog). Consiste en registrar automáticamente todos los parámetros, configuración, entorno… de un experimento en ejecución. Por ejemplo, podría usar Azure ML y la API de seguimiento de MLflow para rastrear automáticamente los parámetros y artefactos del modelo cuando se entrena este.
[vc_row][vc_column][vc_single_image image=»110159″ img_size=»large» alignment=»center» onclick=»link_image»][/vc_column][/vc_row]
Registro automático de MLflow
MLflow define su propia interfaz llamada pyfunc para modelos custom fuera de librerías comunes, que establece una forma común de grabar, restaurar e interactuar con un modelo de aprendizaje automático (junto con el resto de sus dependencias: código, contexto, datos).
Finalmente, MLflow también ofrece soporte automático para las métricas más utilizadas por los científicos de datos, aunque estas se pueden ampliar para incluir otras específicas del modelo. En todos los casos, estas métricas automáticas tienen la misma consideración que el resto de métricas, por lo que se permite buscar y analizar experimentos utilizándolas.
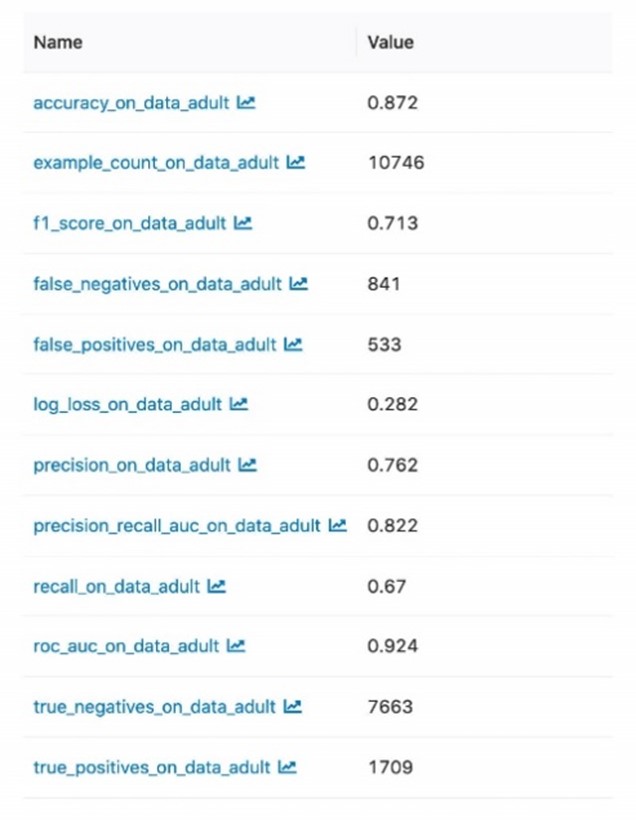
Ejemplo de métricas recopiladas
Registro y reproducibilidad de modelos
El desarrollo de modelos de machine learning puede considerarse un proceso iterativo, en el que es un desafío realizar un seguimiento del trabajo a medida que avanza el desarrollo. Entre los posibles cambios que se introducen, encontramos:
- Conjuntos de datos y su preparación, que cambian constantemente a medida que se desarrolla el modelo y se verifica qué características son las más importantes, agregando características compuestas, eliminando correlaciones, etc.
- Los modelos pueden cambiar. Por ejemplo, el ajuste fino de los parámetros del modelo se puede realizar utilizando diferentes herramientas como Hyperopt.
- El código fuente evoluciona con el tiempo debido a refactorizaciones, correcciones de errores, etc.
Es en este contexto donde se construye el Model Store, componente que gestiona y almacena los diferentes elementos asociados del entrenamiento del modelo y mantiene la trazabilidad de este. La información almacenada puede utilizarse para propósitos como:
- Crear entornos de ejecución, como el utilizado originalmente para entrenar el modelo (en caso de que sea necesario validar el procedimiento de entrenamiento por requerimientos de negocio).
- Analizar la información de entrenamiento y calcular los mejores parámetros del modelo.
Una convención utilizada en varias plataformas de aprendizaje automático es tener un contenedor denominado experimento, que representa la unidad principal de organización de la información almacenada en el tracking server. Cada experimento contiene varias ejecuciones de entrenamiento, por lo que todas las ejecuciones pertenecen a un solo experimento. Cada ejecución registra las fuentes de datos, el código y los metadatos utilizados. Los metadatos más permitidos son:
- Código fuente.
- Fecha de inicio / fecha de finalización del proceso de formación.
- Parámetros.
- Métricas. Las métricas se muestran comúnmente en las visualizaciones.
- Etiquetas. A diferencia de otros metadatos, esta información se puede modificar después de la ejecución.
- Artefactos: las ejecuciones también almacenan archivos de cualquier tipo, de modo que el modelo entrenado se incluya como parte de los artefactos (serializados como pkl o cualquier formato compatible). También es común encontrar archivos de datos (por ejemplo, en formato Parquet), imágenes (por ejemplo, una visualización de la importancia de las características utilizando SHAP) o instantáneas del código fuente.
Implementación del modelo
Una vez que el modelo con el que experimentamos está listo y terminamos la etapa de exploración, es necesario llevarlo a producción. Recuerda que a cualquier modelo que no esté en producción no se le otorga ningún retorno de inversión.
MLflow y Azure Machine Learning
Después de registrar nuestro modelo, tenemos que decidir cómo vamos a implementarlo. En este caso, hay varias formas de implementar un modelo en producción; por ejemplo, utilizando MLflow y Azure Machine Learning:
- PySpark UDF: gracias a las diferentes funciones de MLflow, el modelo se puede exportar a una función PySpark UDF para realizar una inferencia directa a través de Databricks.
- Azure Machine Learning Workspace (AzML): por otro lado, si deseas productizar un servicio web, la mejor opción es exportar el modelo usando las funciones de AzML. En este caso, podrías:
- Registrar el modelo que se implementará en el espacio de trabajo.
- Generar una imagen de Docker.
- Implementar un servicio web a través de Azure Container Instance (para probar el modelo en un servicio web) o directamente al AKS de producción, donde se indicará la configuración de implementación necesaria del pod de Kubernetes.
Esto cubriría la parte de implementación del modelo, pero aún es necesario automatizar este proceso. En el caso de CI/CD en código, está claro que, cuando se hace push del código, debe pasar algunas pruebas y validaciones para que no haya errores en producción y funcione correctamente. Sin embargo, el ciclo de un modelo ML es más complejo.
El flujo de vida de un modelo se compone de:
- Preparación de los datos disponibles para ser consumidos.
- Análisis exploratorio de datos para poder entender que los datos dan respuesta a las preguntas de negocio.
- Una vez validados los datos, se procede a transformar los datos para obtener las características necesarias en el feature engineering.
- Con estos datos, se pasa al entrenamiento de modelos donde se seguirán diferentes aproximaciones y se seleccionará el más adecuado.
- Escogido el mejor modelo, se pasará a validar antes de su despliegue.
- Se despliega el modelo en los diferentes entornos.
- Por último, monitorizaremos el rendimiento del modelo para que no tengamos problemas futuros y podamos analizar cualquier degradación.
Como puede observarse, aunque sea más complejo que el ciclo de vida de código, hay que adaptar el ciclo de DevOps para ellos. En este caso, podemos usar pipelines de Azure dentro de Azure DevOps, pero hay otras herramientas que también resuelven la problemática. Un ejemplo de pipeline que se construiría es el siguiente:
- Se hace un push del código del modelo.
- Por otro lado, se agregan la configuración de entrenamiento necesaria y los conjuntos de validación requeridos para evaluar el desempeño del modelo.
- Una vez configurado, el modelo se entrena y valida con la configuración proporcionada, con todas las validaciones necesarias agregadas.
- Pasadas estas validaciones, es necesario construir el Docker.
- Docker se almacena en Azure Container Registry.
- Finalmente, la imagen de Docker se despliega en AKS para iniciar el servicio web.
Todas estas tareas se pueden configurar, o se pueden establecer diferentes pipelines según la pieza de código en producción o el modelo de machine learning. Además, esto permite mucha versatilidad en la automatización del pipeline específico que mejor se adapte a las necesidades del servicio.
Por lo tanto, los pipelines podrían tomar el modelo entrenado, realizar validaciones e implementarlo después. En conclusión, se propone el uso conjunto de MLflow, Azure Machine Learning Workspace y Azure DevOps para llevar a cabo la integración y despliegue continuo de diferentes modelos de machine learning.
Monitorización de modelos
Desplegar su modelo en producción no es el final, es solo el comienzo para producir un impacto positivo en su negocio. Sin embargo, necesitarías vigilancia de lo que ya desarrollaste y garantizar que tu modelo está acertando con sus respuestas. Por todas estas razones, es necesario monitorizar su modelo.
tanto los datos de entrada como las predicciones del modelo son monitorizadas para analizar las propiedades estadísticas (data drift, rendimiento del modelo, etc.) y el rendimiento computacional (errores, flujo, etc.). Estas métricas pueden ser publicadas en cuadros de mandos o llegar a través de alertas. En concreto, podemos dividir la monitorización en cuatro partes:
- Ingestión de datos: se almacena el funcionamiento de los datos en este paso inicial.
- Se comprueba la precisión de salida del modelo y el data drift. Para ello, se analizan los datos de entrada y las predicciones para comprobar cúal es el estado del modelo en el entorno correspondiente. En esta fase también se puede almacenar información del rendimiento de la infraestructura para acortar la respuesta del modelo.
- Todos estos datos son publicados en diferentes cuadros de mando para poder acceder fácilmente a ellos. Sin embargo, también pueden servir para desencadenar alarmas u otros procesos com, por ejemplo, el reentrenamiento de modelos.
Por ejemplo, en caso de que esté utilizando Azure, puede habilitar Azure Applications Insights para conocer el estado de su propio servicio. Con este servicio habilitado se definen paneles en tiempo real para que el equipo de desarrollo conozca el estado del sistema y resuelva problemas que afectan negativamente el rendimiento de la aplicación.
También está disponible el acceso a los seguimientos del servicio implementado y, al implementar el servicio a través de AzML, se puede habilitar la recopilación de datos para los datos de entrada. Esto permite un aumento en los datos de entrada para los modelos y errores de reproducción en caso de que el modelo no responda correctamente.
[vc_row][vc_column][vc_single_image image=»110178″ img_size=»large» alignment=»center» onclick=»link_image»][/vc_column][/vc_row]
Un ejemplo de seguimiento de código usando Applications Insights
Como en muchos casos los servicios de producción consisten en un AKS, el estado de estos servicios se puede consultar a través del panel proporcionado por Kubernetes. Conocer el estado de los servicios y la salud de los diferentes pods (ver figura inferior) es fundamental.
[vc_row][vc_column][vc_single_image image=»110184″ img_size=»large» alignment=»center» onclick=»link_image»][/vc_column][/vc_row]
Te ayudamos a desarrollar tu estrategia de ciclos MLOps
En Plain Concepts contamos con equipos especializados en el desarrollo de estrategias de machine learning para automatizar procesos o aprovechar el potencial combinado de los datos y la inteligencia artificial.
El machine learning permite así crear ofertas o productos personalizados para los clientes y realizar ciertas tareas mecánicas en menos tiempo con la misma eficacia. De esta forma, tú y tu equipo estáis más satisfechos y os podéis dedicar a otras labores.
Trabajamos contigo para dar un nuevo rumbo a tu empresa a través del machine learning. ¿En qué podemos ayudarte?

Categorías
Post Relacionados
5min. read
La resiliencia digital, clave para proteger el futuro del sector sanitario
3min. read
Plain Concepts, reconocido como Microsoft Fabric Featured Partner
Plain Concepts ha sido reconocido como Microsoft Fabric Featured Partner por su experiencia en el diseño e implementación de plataformas de datos modernas, escalables y preparadas para impulsar la inteligencia artificial.
4min. read
CompactifAI en n8n: IA eficiente integrada en workflows reales
Plain Concepts Research y Multiverse lanzan un community node open source que integra los modelos de IA comprimidos de CompactifAI en los workflows de n8n.