
Elena Canorea
Communications Lead
Durante más de una década, las redes neuronales convolucionales han dominado la investigación de la visión por computación. Sin embargo, la irrupción de nuevas topologías como los Vision Transformers, han ayudado al desarrollo de técnicas que mejoran la eficiencia y los resultados de tareas como la clasificación, detección de objetos y segmentación semántica de imágenes.
Las redes neuronales convolucionales son un tipo de red neuronal artificial donde las neuronas corresponden a campos receptivos muy similares a los de la corteza visual primaria de un cerebro humano.
Estas redes son capaces de aprender en los diferentes niveles de abstracción, como los colores, formas simples, combinaciones de bordes y, en la última capa, pone atención en la forma para averiguar qué es exactamente.
Las redes neuronales convolucionales están formadas por distintas capas que están especializadas en la operación de convolución. Dentro del campo de visión por computación, esta operación permite aprender patrones locales en ventanas pequeñas de dos dimensiones.
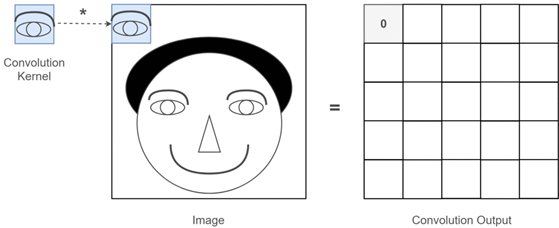
Otra característica importante es que las capas convolucionales pueden aprender jerarquías espaciales de patrones preservando las relaciones espaciales. Por ejemplo, una primera capa convolucional puede aprender elementos básicos como los bordes, y una segunda capa convolucional puede aprender patrones compuestos de elementos básicos aprendidos en la capa anterior.
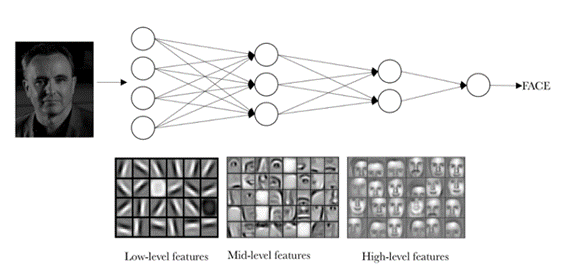
Como podemos apreciar en la imagen anterior, una red neuronal puede estar compuesta por distintas capas de convolución. Cada capa aprenderá distintos niveles de abstracción con el objetivo global de entender de una manera eficiente conceptos visuales cada vez más complejos.
Uno de los grandes avances que surgieron durante el año pasado fue la inclusión de nuevas topologías de redes neuronales dentro del campo de visión por computación. Estas nuevas topologías han revolucionado la manera convencional con la que se utilizan las redes neuronales convolucionales para resolver típicas tareas de visión por computación como: clasificación, detección de objetos y segmentación de imágenes.
La irrupción de los Transformers (los cuales solo se habían utilizado hasta ahora para tareas de procesamiento de lenguaje natural) en el campo de la visión por computación mejoró notablemente la capacidad de estas topologías para extraer las características de las imágenes. Y, por lo tanto, mejorar la tasa de acierto en los respectivos benchmarks de imageNet.
Para una red neuronal convolucional, ambas imágenes son casi iguales, ya que las redes neuronales convolucionales no codifican la posición relativa de diferentes características. Se requerirían filtros muy grandes para codificar la codificar dicha información: Por ejemplo, “ojos encima de nariz”.
El mecanismo de atención proporcionado por los Transformers junto con las redes neuronales convolucionales ayuda a modelar dependencias de largo alcance sin comprometer la eficiencia computacional y estadística.
Desde el momento de la aparición del primer Vision Transformers, muchos de los departamentos de investigación de universidades y grandes empresas empezaron a realizar distintas pruebas con arquitecturas híbridas que combinaban el mecanismo de atención con los beneficios de las redes neuronales convolucionales en la extracción de características “ConvMixers”.
Las distintas topologías de redes surgidas durante estos años han hecho que muchos de los grupos de investigación vuelvan a revisar las técnicas utilizadas hasta ahora y hayan puesto el foco en mejorar, cada vez más, la eficiencia y la tasa de acierto de las redes neuronales convolucionales. Tanto es así, que en lo poco que llevamos de año, ha aparecido una nueva topología llamada ConvNext, la cual fue presentada por Facebook research, y que ha superado a las arquitecturas de Vision Transformers utilizando solamente redes neuronales convolucionales.
Sin duda, durante este año veremos muchas más topologías de redes neuronales que podrían revolucionar de nuevo el paradigma de la visión por computación tal y como lo conocíamos hasta ahora.
Si quieres saber más sobre Visual Transformers, no te pierdas la charla «¿Es este el final de las redes neuronales convolucionales? Welcome Vision-Transformers» del Singularity Tech Day 2021

Elena Canorea
Communications Lead
