
Elena Canorea
Communications Lead
Son tiempos convulsos en los que vivimos estos días y mantenernos ocupados es una buena manera de llevar la situación. Es por esto que hoy vamos a hablar sobre cómo crear una base de datos en alta disponibilidad utilizando MongoDb y su característica de Replica Set. Hace unas semanas hablamos sobre como crear aplicaciones de alto rendimiento, tanto en lo que se refiere a escribir código de alto rendimiento como a escribir un logger de alto rendimiento pero… por muy bien que funcione una sistema en cuanto a rendimiento, ¿qué podemos hacer si trabajamos con una base de datos y esta tiene un fallo? ¿De qué sirve el trabajo de optimizar si luego se cae la base de datos?
Pues sencillamente el sistema deja de funcionar, no hay más. Para poder solventar esas situaciones donde no se puede tolerar que el sistema falle se utilizan sistemas de alta disponibilidad que no es más que el hecho de haya redundancia de los elementos. Aunque es una explicación grosso modo, lo que se consigue al redundar los elementos es que si uno falla otro pueda seguir dando el servicio mientras se arregla la situación.
Esto es algo relativamente sencillo cuando tenemos una API a la que llamamos y contra la que trabajamos, si la API carece de estado basta con que llamemos a otra instancia y todo funciona bien. El problema se complica cuando es necesario que los datos que contiene se compartan entre las diferentes instancias del servicio. Una vez más, si ponemos el ejemplo de una API, se podría persistir el estado en una base de datos desde la que consuman los datos de estado todas las instancias, pero… ¿Dónde compartimos los datos si lo que queremos es redundar la base de datos?
En el caso de una base de datos parece claro que no es suficiente el hecho de apuntar a otra y ya está, puesto que esa otra no va a tener los datos ya registrados en las tablas…
Vale, acabamos de plantear una base de datos de alta disponibilidad no es algo banal y que no basta con cambiar de una instancia a otra y ya está. Entonces, ¿cómo funciona una base de datos en alta disponibilidad?
Para poder conseguir que una base de datos funcione en alta disponibilidad lo que vamos a necesitar es agrupar diferentes instancias y conseguir que se comporten como una sola (Cluster). Ciertamente como hacer esto depende mucho del tipo de motor de base de datos que estemos utilizando. Algunos motores soportan esto de manera añadida y otros fueron pensados desde el principio para poder trabajar de manera distribuida. No es lo mismo montar un Sql Server en alta disponibilidad que un MongoDb en alta disponibilidad, ni en el hardware necesario ni en el trabajo de configuración.
MongoDB es una base de datos documental NoSQL que desde el principio se pensó para trabajar de manera distribuida utilizando el modelo de maestro-esclavo con hasta 50 nodos a fecha actual. El hecho de que sea maestro-esclavo quiere decir que las operaciones de escritura se deben realizar sobre el maestro y este es el que se preocupa de replicar los datos sobre el resto de nodos del sistema. Pese a que planteado así puede parecer que si el maestro cae el sistema deja de funcionar, MongoDB está pensado para trabajar en alta disponibilidad y tiene la capacidad de que los nodos esclavos elijan un nuevo maestro en el caso de que este falle.
El diagrama de funcionamiento es este:
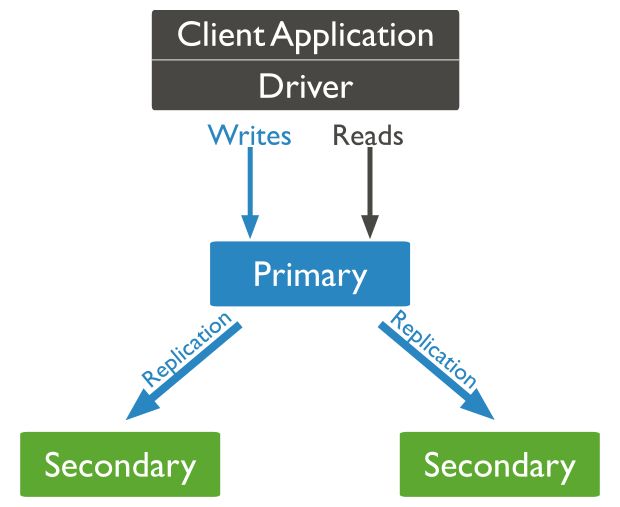
Si tienes interés en conocer cómo funciona en profundidad la replicación en MongoDB, te dejo un enlace a la documentación oficial.
Nuestras aplicaciones se conectarán directamente al nodo primario y este es el que se encargará de que los datos se repliquen sobre los nodos secundarios.
Para conseguir este funcionamiento de alta disponibilidad en mongoDB, existe el concepto de ReplicaSet. Este ReplicaSet es el conjunto de los diferentes nodos (instancias de mongoDB) conectados entre ellos de modo que consigamos alta disponibilidad.
Una de las ventajas de mongoDB es que ha sido pensada para trabajar de manera distribuida, de modo que si un nodo se cae el resto puedan asumir el trabajo y el sistema no se vea afectado. Aunque a día de hoy un ReplicaSet soporta hasta 50 nodos, el mínimo número de nodos para tener un mongoDB en alta disponibilidad es 2. Es por esto que es necesario que mongoDB se esté ejecutando en al menos dos servidores.
MongoDB no trabaja con ficheros de configuración por defecto, por lo que podemos indicarle las diferentes configuraciones al arrancar mediante parámetros del comando, o crear un fichero de configuración e indicarle en el arranque que queremos utilizarlo. Para ello basta con arrancar el proceso utilizando:
mongod --config <ruta al fichero de configuración>
Una vez que tenemos claro como arrancar la instancia de mongoDB para trabajar con un fichero de configuración, vamos a crearlo y a añadir en el la propiedad net.bindingIp para hacer que cada instancia escuche peticiones desde las IPs del resto de instancias. En caso de no hacerlo, solo podríamos hacer llamadas desde localhost hacia esa instancia de mongoDB y no podríamos crear el ReplicaSet.
MongoDB soporta diferentes formatos de ficheros de configuración, pero por su sencillez vamos a utilizar yaml. Por ejemplo nuestro fichero de configuración ahora mismo sería algo así:
net:
bindIp: localhost,<ip address>,<ip address>
Podemos indicar varias IPs utilizando coma ‘,’ entre las diferentes IPs. En caso de querer permitir llamadas desde cualquier dirección, bastaría con utilizar ‘::’ para cualquier dirección IPv6 y ‘0.0.0.0’ para cualquier dirección IPv4.
Sobre ese mismo fichero, vamos a añadir el nombre del ReplicaSet al que pertenece la instancia con la propiedad replication.replSetName. En este caso yo lo he llamado rs0, por lo que mi fichero de configuración completo es así:
net:
bindIp: ::,0.0.0.0
replication:
replSetName: "rs0"
Estas dos propiedades de configuración tienen que estar en cada uno de los nodos que van a componer el ReplicaSet ya que todos los nodos tienen que ser accesibles entre ellos y compartir ReplicaSet. No es relevante si un nodo se configura mediante fichero y otro mediante parámetros, pero tienen que estar configuradas.
Con esto, ya estamos listos para funcionar :). Vamos a entrar en cada uno de los servidores mongoDB utilizando el cliente de mongo simplemente ejecutando desde la consola local (de cada servidor):
mongo
Y en cada uno de ellos crearemos un usuario:
use admin
db.createUser(
{
user: "admin",
pwd: "password",
roles: [ { role: "userAdminAnyDatabase", db: "admin" }, "readWriteAnyDatabase" ]
}
)
Recapitulemos, tenemos varias instancias de mongo corriendo, todas configuradas para trabajar en alta disponibilidad. ¿Ya esta todo hecho? La verdad es que aun no… Con estos pequeños pasos hemos conseguido tener todo preparado, pero falta iniciarlo todo.
Desde cualquiera de los servidores pero solo desde uno, vamos a entrar en la consola y vamos a ejecutar rs.initiate() indicándole los datos de los servidores. Por ejemplo en mi caso:
rs.initiate(
{
_id : "rs0",
members: [
{ _id : 0, host : "40.118.22.136:27017" },
{ _id : 1, host : "13.73.148.195:27017" },
{ _id : 2, host : "13.73.144.190:27017" }
]
}
)
En este comando, aparte de otros datos que podríamos informar si nos hiciese falta, le estamos indicando el nombre del ReplicaSet, así como la dirección de cada uno de sus miembros. Una vez ejecutado el comando podemos utilizar rs.status() para ver el estado en el que se encuentra el cluster:
rs0:PRIMARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2020-03-22T00:11:25.958Z"),
"myState" : 1,
"term" : NumberLong(6),
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
},
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
},
"appliedOpTime" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
},
"durableOpTime" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
}
},
"members" : [
{
"_id" : 0,
"name" : "40.118.22.136:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1702,
"optime" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
},
"optimeDate" : ISODate("2020-03-22T00:11:23Z"),
"electionTime" : Timestamp(1584834202, 1),
"electionDate" : ISODate("2020-03-21T23:43:22Z"),
"configVersion" : 1,
"self" : true
},
{
"_id" : 1,
"name" : "13.73.148.195:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 1694,
"optime" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
},
"optimeDurable" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
},
"optimeDate" : ISODate("2020-03-22T00:11:23Z"),
"optimeDurableDate" : ISODate("2020-03-22T00:11:23Z"),
"lastHeartbeat" : ISODate("2020-03-22T00:11:25.174Z"),
"lastHeartbeatRecv" : ISODate("2020-03-22T00:11:25.173Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "40.118.22.136:27017",
"configVersion" : 1
},
{
"_id" : 2,
"name" : "13.73.144.190:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 1679,
"optime" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
},
"optimeDurable" : {
"ts" : Timestamp(1584835883, 1),
"t" : NumberLong(6)
},
"optimeDate" : ISODate("2020-03-22T00:11:23Z"),
"optimeDurableDate" : ISODate("2020-03-22T00:11:23Z"),
"lastHeartbeat" : ISODate("2020-03-22T00:11:25.174Z"),
"lastHeartbeatRecv" : ISODate("2020-03-22T00:11:24.934Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "13.73.148.195:27017",
"configVersion" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1584835883, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1584835883, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Adicional a la información sobre el propio cluster, podemos encontrar cosas como información sobre cada nodo. Alguna información útil sobre el nodo nos dice si es primario o secundario, cuando llego el último latido de vida, o el tiempo que lleva en marcha.
¡¡Ahora sí que tenemos una base de datos mongoDB en alta disponibilidad!!
Ahora mismo tenemos un cluster mongoDB en alta disponibilidad listo y funcionando, pero… ¿qué pasa si tenemos que añadir o borrar nodos?
Imagina que por la razón X uno de los servidores de cluster se va a parar durante un tiempo para hacer ciertas labores. Para que el propio cluster sea capaz de elegir al maestro, tienen que estar disponibles la mayoría de nodos del cluster. En un cluster de 4 nodos, la mayoría son 3, si ya estamos quitando uno de los 4 para hacer mantenimientos pero el cluster no lo sabe, cuando uno falle no será capaz de elegir un nuevo maestro ya que necesita que 3 nodos estén de acuerdo, pero solo nos quedan 2… (recuerda que el cluster piensa que tiene 4).
Para esto mongoDB nos ofrece 2 sencillos comandos que podemos ejecutar desde el servidor primario y nos va a permitir añadir y eliminar nodos del cluster. Estos comandos son rs.remove() y rs.add().
Estos comandos reciben como parámetro la dirección del nodo que queremos añadir o eliminar y se encarga de hacer que todo se configure para seguir funcionando. Por ejemplo en mi caso si quiero eliminar un nodo y volverlo a añadir de que acabe las labores sería algo así:
rs.remove("13.73.144.190:27017")
........
rs.add("13.73.144.190:27017")
MongoDB es una base de datos NoSQL más que probada y muy robusta que podemos utilizar en nuestros desarrollos sin ningún problema, pero hay que tener en cuenta que no es una base de datos relacional. Esto tiene sus ventajas y sus desventajas y el hecho de que la replicación y la alta disponibilidad se consiga fácilmente no quita que sea necesario estudiar si es una solución apropiada o no. Es una base de datos pensada para trabajar de manera distribuida y eso es lo que hace que mongoDB se pueda utilizar de manera muy sencilla en alta disponibilidad.
Para acabar, en esta entrada hemos hablado por encima del funcionamiento de mongoDB y hemos hecho una configuración básica de un ReplicaSet. Lo que busco escribiendo esta entrada no es explicar al 100% los entresijos de mongoDB y las diferentes configuraciones que ofrece, ya que eso da para un libro (y de hecho los hay), sino hablar de un potente motor NoSQL y poner un ejemplo de cómo crear una alta disponibilidad.
Si tienes alguna duda concreta sobre como hacerlo o cómo diseñar el sistema en concreto, déjame un comentario o un mensaje y vemos el caso más a fondo.
Todo lo que hemos planteado está muy bien, pero la realidad es que no es práctico tener que crear un cluster de mongoDB para el desarrollo del día a día. Para poder conseguir de manera sencilla un cluster de mongoDB en local, podemos utilizar docker y crearlo de una manera muy sencilla.
Lo primero que vamos a necesitar es tener Docker instalado (por supuesto) y crear un fichero docker-compose.yml como este:
version: "3"
services:
mongo0:
hostname: mongo0
container_name: mongo0
image: mongo
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: example
ports:
- 27017:27017
restart: always
entrypoint: [ "/usr/bin/mongod", "--bind_ip_all", "--replSet", "rs0" ]
mongo1:
hostname: mongo1
container_name: mongo1
image: mongo
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: example
ports:
- 27018:27017
restart: always
entrypoint: [ "/usr/bin/mongod", "--bind_ip_all", "--replSet", "rs0" ]
mongo2:
hostname: mongo2
container_name: mongo2
image: mongo
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: example
ports:
- 27019:27017
restart: always
entrypoint: [ "/usr/bin/mongod", "--bind_ip_all", "--replSet", "rs0" ]
mongo-express:
container_name: mongo-client
image: mongo-express
restart: always
ports:
- 8081:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: root
ME_CONFIG_MONGODB_ADMINPASSWORD: eample
ME_CONFIG_MONGODB_SERVER: "mongo0,mongo1,mongo2"
Gracias a este fichero docker-compose vamos a crear 3 instancias de mongoDB y además vamos a levantar también un cliente web donde poder ver que todo funciona.
Simplemente vamos a ejecutar:
docker-compose up -d
Y una vez que se levanten los contenedores, vamos a entrar en una instancia cualquiera de mongo y vamos a poner en marcha el Replica Set. Por ejemplo, si eligiésemos el contenedor mongo0:
docker exec -it mongo0 mongo
# Y una vez dentro de mongo
config={"_id":"rs0","members":[{"_id":0,"host":"mongo0:27017"},
{"_id":1,"host":"mongo1:27017"},{"_id":2,"host":"mongo2:27017"}]}
rs.initiate(config)
Simplemente con esto ya hemos creado el Replica Set y tenemos una base de datos mongo en alta disponibilidad corriendo todo en local sobre docker. Podemos ver que todo está funcionando si entramos en el cliente web en http://localhost:8081/ . De hecho, podemos comprobar fácilmente que las elecciones del nodo primario están ocurriendo simplemente si paramos el contenedor del nodo primario y refrescamos la web. En el apartado hostname vamos a ver que nodo está actuando como primario.
Gracias a docker es muy fácil jugar con mongoDB y probar que sucede cuando un nodo se cae, o montar un cluster de más de 2-3 nodos. Me ha parecido útil añadir este último apartado sobre como hacer lo mismo con docker para que puedas probar y trastear con mongoDB, ya que es una opción muy interesante. Pero recuerda, docker no es lo ideal para poner una base de datos en alta disponibilidad en entornos de producción, úsalo solo con fines de desarrollo y pruebas.
Entrada orginalmente publicada en Fixebuffer.com
Elena Canorea
Communications Lead
