
Elena Canorea
Communications Lead
Los datos libres u Open Data son una iniciativa de las Administraciones Públicas para que determinados datos e informaciones sean accesibles y al alcance de todos. La intención de esta práctica es la de permitir su reutilización para conseguir beneficios para empresas y ciudadanos. Sin embargo, acceder a ellos y analizarlos de forma correcta puede tornarse complicado.
En este artículo vamos a abordar los factores más sencillos y el análisis de estas fuentes de datos, poniendo como ejemplo el sistema que fija el precio de la electricidad y como estos «open data» terminan influyendo en nuestras facturas.
El mercado de energía eléctrica en España está compuesto por 4 agentes principales: los generadores (compañías que generan energía eléctrica), transporte (transmite electricidad de alta tensión hasta los distribuidores), distribuidores (distribuyen energía eléctrica de baja y media tensión hasta los consumidores) y comercializadores (comercializan la energía eléctrica, mayoritariamente focalizados en el sector residencial).
Estos 4 agentes se reparten el pastel representado en la factura eléctrica que llega hasta el consumidor. Mientras que los costes del transporte y la distribución podemos considerarlos fijos, son los costes de los generadores y los consumidores los responsables de la volatilidad del precio de la energía eléctrica. Los consumidores que tengan una tarifa libre (60% de los consumidores tiene esta tarifa según CNMC) están más protegidos frente a la volatilidad de los precios, pero normalmente los consumidores con tarifa regulada (PVPC – precio voluntario para pequeño consumidor) obtienen mejores condiciones ya que pagan la electricidad a precio de mercado.
Como hemos dicho anteriormente, la tarifa regulada está fuertemente influenciada por el precio real de mercado, el cual se puede representar utilizando una clásica curva de oferta y demanda. Esta curva muestra la relación entre la cantidad demandada y el precio ofertado dentro del mercado. El precio de la energía eléctrica resulta del equilibrio (intersección, casación) de ambos componentes (demanda y oferta)
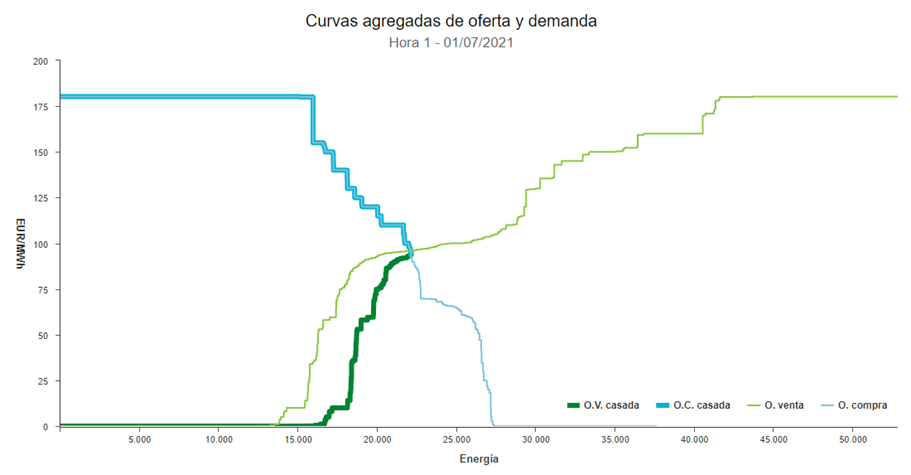 En la curva de oferta (venta), el precio de la energía es linealmente proporcional a la cantidad ofertada (a medida que el precio aumenta, también aumenta la cantidad ofrecida, teniendo en cuenta que existe un precio máximo establecido por ley)
En la curva de oferta (venta), el precio de la energía es linealmente proporcional a la cantidad ofertada (a medida que el precio aumenta, también aumenta la cantidad ofrecida, teniendo en cuenta que existe un precio máximo establecido por ley)El día anterior al consumo real de la electricidad se realiza la casación entre la oferta y demanda, basada en las predicciones enviadas por los agentes del sistema (principalmente generadores y distribuidores). La casación comienza ordenando las ofertas de los agentes generadores de menor a mayor precio (las ofertas más baratas suelen corresponder a energías de origen nuclear, seguidas de las renovables, ciclo combinado, hidráulica y carbón, aproximadamente), y después se calcula cuál es la última oferta con la que se garantiza la demanda estimada de los consumidores. El precio de esta última oferta es el precio marginal que se paga a todos los agentes generadores (aunque su cuota de energía sea o no consumida, o su coste de producción fuera mayor o menor). Este tipo de subasta se denomina marginalista.
Una primera aproximación para el análisis y predicción del precio de la energía eléctrica sería descomponer el problema en el estudio de estas dos curvas, y los factores que pueden influenciar cada componente.
Los factores implicados tanto en la curva de oferta como en la de demanda, pueden ser diversos y sufrir complejas interrelaciones. Pero para limitar el alcance de este artículo, nos limitaremos al estudio de los factores más sencillos.
La cantidad consumida puede depender fácilmente de factores meteorológicos (por ejemplo, a mayor calor mayor necesidad energética para cubrir las necesidades de aires acondicionados y climatizadores). En España existe mucha actividad dedicada al turismo, así también sería fácil pensar que en el sector terciario puede provocar un aumento de energía debido al aumento de la actividad empresarial. Finalmente, también podemos entender que la demanda puede estar influenciada por el propio calendario laboral (por ejemplo, la actividad industrial puede ser inferior los fines de semana y festivos).
Por otra parte, entre los factores que pueden afectar a la oferta de energía, volvemos a contar con los factores meteorológicos, que pueden afectar en gran medida a la producción de energías renovables (principalmente, tenemos energía solar, eólica y geotérmica). En algunos casos, también debemos tener en cuenta el coste de la materia prima (por ejemplo, el precio del gas), sus interrelaciones con otras materias primas en mercados nacionales / internacionales (por ejemplo, el coste de barril Brent) y los costes derivados de su consumo (por ejemplo, derechos de emisión de CO2). También en cierta medida podríamos observar otros factores más especulativos (por ejemplo, utilizando el precio de las acciones de las empresas que intervienen en el sistema).
En el caso de soluciones de Business Intelligence o de Machine Learning, el dato se convierte en el componente principal del sistema. Por ello debemos prestar especial importancia a todo lo relacionado con el dato, y en especial si éste dato proviene de la integración con sistemas terceros. Desde este punto de vista, existen diversos factores a la hora de analizar estas fuentes de datos:
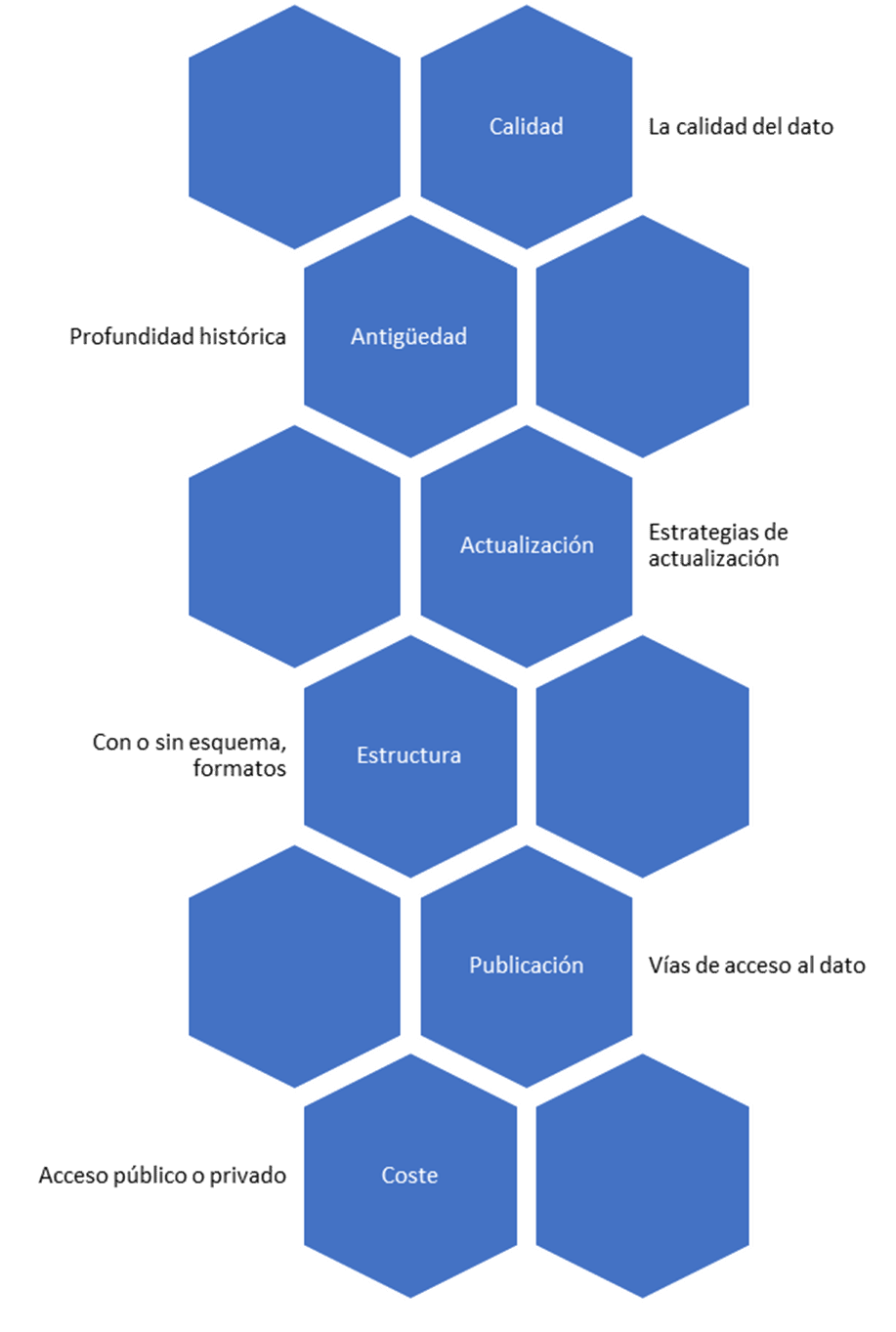 Las fuentes de información tienen diferentes costes de explotación. De esta manera, la integración de fuentes públicas y gratuitas normalmente es mucho más sencilla y rápida, aunque la calidad y cantidad de datos puede ser mayor cuando se utilizan fuentes de datos privadas. Respecto al tipo de información, es mucho más complejo procesar datos almacenados en imágenes (jpeg, PDF), texto (ficheros Word) o en páginas web que requieren complejos procesos de recolección (web scrapping).
Las fuentes de información tienen diferentes costes de explotación. De esta manera, la integración de fuentes públicas y gratuitas normalmente es mucho más sencilla y rápida, aunque la calidad y cantidad de datos puede ser mayor cuando se utilizan fuentes de datos privadas. Respecto al tipo de información, es mucho más complejo procesar datos almacenados en imágenes (jpeg, PDF), texto (ficheros Word) o en páginas web que requieren complejos procesos de recolección (web scrapping).
Por estos motivos, es preferible obtener los datos en formatos que son fácilmente procesables de manera programática, como pueden ser los formatos tabulares (utilizando formato CSV, parquet o incluso ficheros Excel). Igualmente, en un principio acceder a una fuente offline puede ser más sencillo, pero muchas veces necesitaremos una actualización continua de la información, para lo cual los sistemas online son más versátiles.
A continuación, estudiaremos algunas de las fuentes de datos que podemos utilizar para analizar las curvas de oferta y demanda. Esta selección representa una muestra de los diferentes escenarios que podemos encontrar a la hora de gestionar y procesar datos de fuentes externas.
El precio de la energía eléctrica es el dato principal de nuestro estudio. Este dato encuentra disponible desde la web de OMIE (Operador del Mercado Ibérico de Energía), donde se pueden ver el precio de la energía del día actual, a nivel horario. Como hemos explicado anteriormente, la subasta para el día actual se realiza el día anterior, por lo que ya desde entonces es posible saber el precio de la energía a cualquier hora del día.
Pero para la construcción de nuestra solución, no sólo necesitamos los datos a fecha de hoy, sino que necesitamos recopilar datos históricos. ¿Cuánto tiempo tenemos que remontarnos en el pasado? La respuesta de esta pregunta en la mayoría de las ocasiones es un “depende del caso”, probablemente seguido de un “pero toda la disponible es un buen comienzo”.
En nuestro caso, los datos históricos se encuentran disponibles desde la propia web de OMIE, por lo que se puede automatizar su descarga, mediante un procedimiento de scrapping de la página web. El fichero que se descarga es un CSV, cuya cabecera es como sigue:
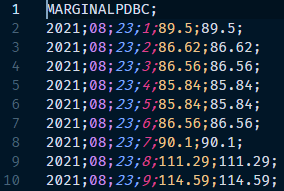
Al analizar el contenido del fichero, empezamos a entender la “complejidad” que puede desencadenar el trabajar con fuentes de datos externas. En este caso, el fichero CSV no tiene ninguna cabecera con los nombres de las columnas, por lo que debemos de “deducirlas”. En nuestro caso, el delimitador de columna es el punto y coma, y el orden de las columnas podría ser: año; mes; día; hora; valor1; valor2.
No tenemos ninguna referencia del valor asociado a las dos últimas columnas del dataset, pero al menos en los datos de muestra, el contenido de la columna valor1 es idéntico a valor2, por lo que podemos deducir que se trata del precio de casación. Pero siempre existe un nivel de incertidumbre al no existir ningún diccionario de datos ni ninguna otra manera de corroborar esta hipótesis, lo cual disminuye la calidad del dato extraído, y hace recomendable buscar otra fuente de datos más fiable.
Los datos meteorológicos parecen afectar tanto a la curva de oferta como a la de demanda, así que sería razonable que fuera una de las primeras fuentes de datos a utilizar. En este caso, existen muchos servicios tanto públicos como privados, que permiten obtener la información meteorológica, tanto a nivel histórico (pasado) como a nivel futuro (predicciones).
VisualCrossing ofrece información del tiempo mediante un API REST. Utilizar un API REST para la recogida de datos ofrece varias ventajas:
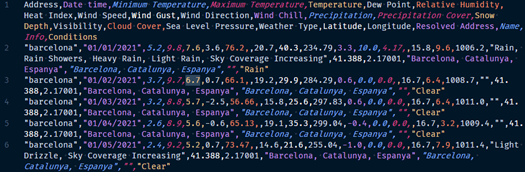
En el extracto de información anterior, podemos observar como la primera línea de la respuesta de la API se corresponde a lo que se denomina “cabecera de CSV” donde se especifica el contenido de la información contenida en cada una de las columnas de los datos.
REE es el agente que opera el sistema eléctrico español. Afortunadamente, cuenta con un API publica que no requiere ninguna autentificación. En este caso, los datos que devuelve la API están en formato JSON.
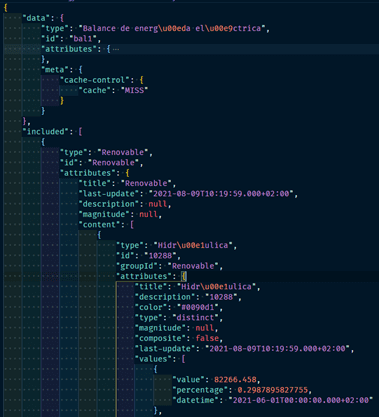
A priori, estos datos pueden presentar una complejidad mayor a la hora de ser procesados, pero, por otra parte, debido a que permiten organizar la información de una manera no lineal, la expresividad de los datos se incrementa. Al contrario que en el caso de la OMIE, REE ofrece una documentación que facilita la explotación y aumenta la calidad del dato.
Dentro de las materias primas utilizadas con fines energéticos, nos centraremos en el caso del gas. MIBGAS (Mercado Ibérico del GAS) es el organismo que regula el mercado de compra/venta de gas, y publica diariamente un precio de referencia. Los índices del año actual se publican en un fichero Excel, que se puede descargar desde la web.
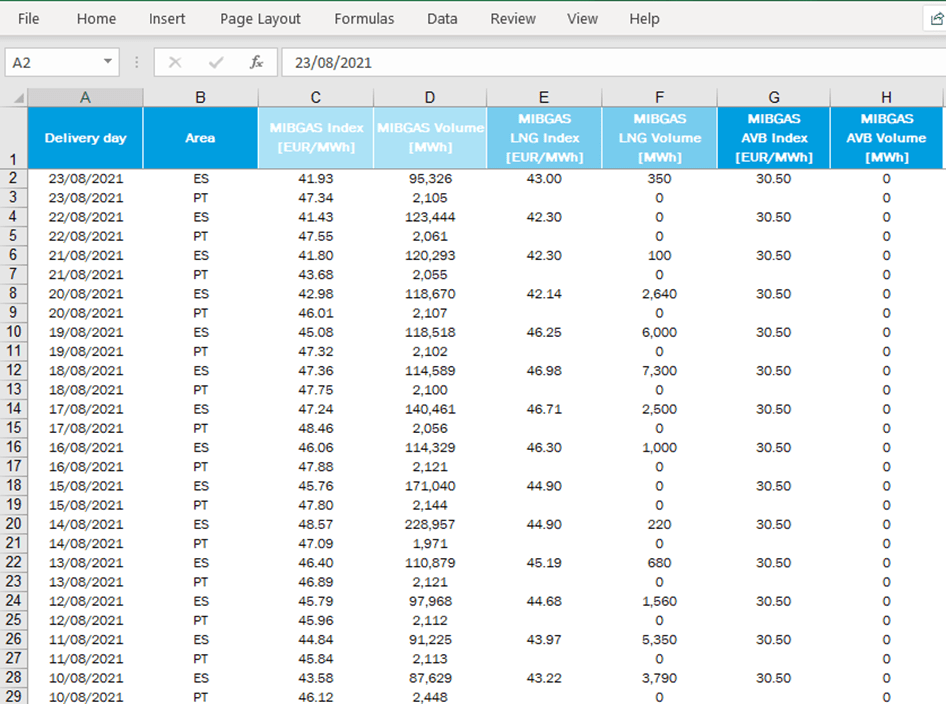 Excel es un formato utilizado extensivamente por personas sin conocimientos de programación, pero también puede ser usado programáticamente para acceder a los contenidos de este y facilitar así su manipulación.
Excel es un formato utilizado extensivamente por personas sin conocimientos de programación, pero también puede ser usado programáticamente para acceder a los contenidos de este y facilitar así su manipulación.
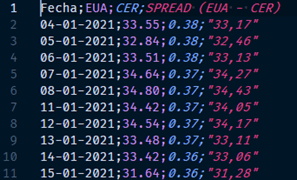
Alternativamente, otro dato interesante asociado al del precio del gas, es el precio de derecho de emisiones de CO2. En este caso, Sendeco2 proporciona un histórico (desde 2008 hasta el año actual) con los precios de los derechos de emisión.
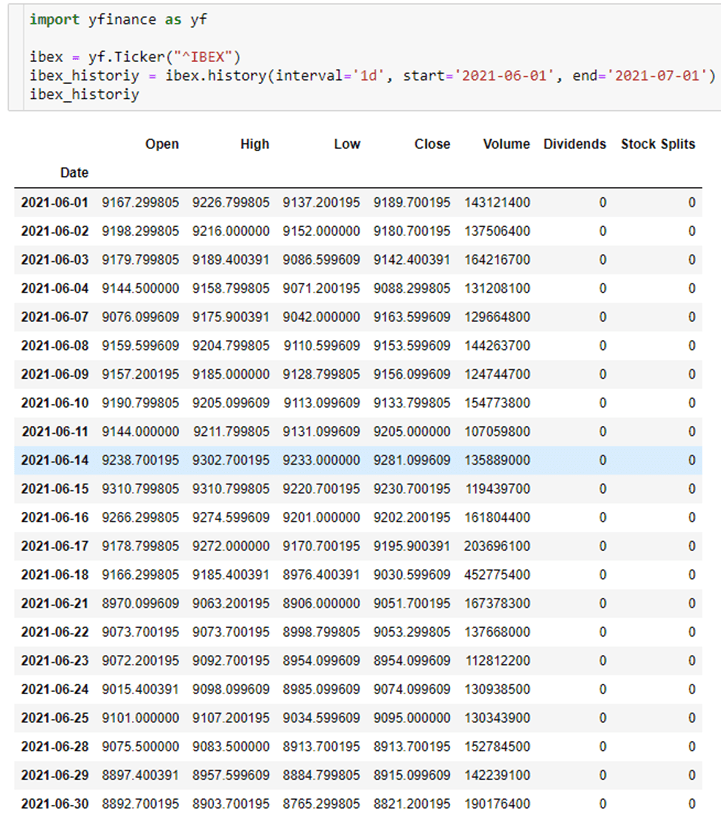
Como indicador del nivel económico del país, podemos utilizar el índice del IBEX35. Este índice se encuentra disponible gratuitamente en Yahoo Finance. En este caso, en vez de utilizar directamente la API, vamos a utilizar una librería open source (yfinance), lo cual ayudará a reducir los tiempos de desarrollo propios. En la siguiente captura se puede observar lo sencillo que resulta obtener los índices del IBEX35, siendo posible también aplicar filtros predeterminados en origen (fecha inicial, fecha final, intervalo de agregación).
 Datos indicadores de actividad
Datos indicadores de actividadEl dataset denominado “COVID-19 Community Mobility Report” es un dataset elaborado por Google, en el cual se puede observar la actividad (ocio/recreo, alimentación/farmacias, parques, estaciones de transporte, zonas de oficina, zonas residenciales) en diferentes sectores geográficos. A diferencia de otras fuentes de datos, este dataset se empezó a recopilar en el 2020, y está ligado a los intereses de Google, por lo que su continuidad a futuro puede verse comprometida.
La información de este dataset está almacenada en un sistema BigQuery, que se puede consultar de manera gratuita y pública. Este es otro caso de la utilización de una librería existente en Python que facilita enormemente la consulta de datos.
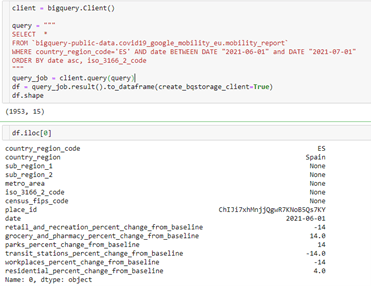
Esta manera de trabajar con el dato tiene las siguientes ventajas:
La siguiente tabla sintetiza diferentes factores a la hora de tener en cuenta la extracción de datos a partir de fuentes de datos externas. Dichos factores pueden ser relevantes a la hora de establecer una estimación acerca de la complejidad de implementar un procedimiento de extracción, transformación y carga (ETL).

En la fase de análisis y experimentación, no es tan importante la automatización del proceso, como el poder extraer el dato para poder evaluar su adecuación al caso de uso. Los siguientes pasos deben ir encaminados a la construcción de un datalake en el que se almacenen los datos provenientes de las diferentes fuentes, así como unos pipelines que hagan posible tanto su ingesta (independientemente del origen) como su posterior transformación.
Este datalake sería la base para la construcción posterior de un Feature Store que sería el que finalmente alimentara el proceso de entrenamiento del modelo de Machine Learning.
Siempre será recomendable utilizar fuentes de datos que permitan obtener el dato en el formato más similar al formato utilizado por las herramientas de análisis. Así, por ejemplo, si los datos están en una página web, primero tendremos que construir una herramienta para leer la información de una página web (formato HTML) y convertirla a una estructura de tipo tabla (compuesta de filas y columnas), de manera que este tipo de datos pueden ser consumido por librerías como Pandas. Por otra parte, es mucho más eficiente si utilizamos por ejemplo una librería como bigquery, que permite realizar consultas complejas y devolver un dato de tipo dataframe. Sin embargo, no es de extrañar que la mayoría de las fuentes de datos suele encontrarse en un punto de madurez intermedio entre los dos ejemplos anteriores.
En este artículo hemos revisado diferentes factores para tener en cuenta a la hora de explotar fuentes de datos externas:
Elena Canorea
Communications Lead
