
Elena Canorea
Communications Lead
Los modelos GPT, desarrollado por OpenAI, se han posicionado como uno de los motores de la inteligencia artificial y el Procesamiento del Lenguaje Natural (NPL). Sus capacidades para crear código y texto similar al humano han hecho que sean una de las grandes revoluciones del momento.
Como especialistas en Azure OpenAI, hemos recopilado algunas de las técnicas avanzadas más importantes en el prompt design y prompt engineering para las APIs con las que cuentan los modelos GPT. ¡Sigue leyendo!
Los modelos GPT-3, GPT-3.5 y GPT-4 se basan en instrucciones. Es decir, el usuario interactúa con el modelo introduciendo una directriz de texto, a la que el modelo responde completando el texto.
Al igual que el resto de modelos de lenguaje generativo, los modelos GPT intentan reproducir la siguiente serie de palabras que es más probable que sigan al texto anterior, como si fuese un humano el que lo está escribiendo. A medida que se desarrollan indicaciones más complejas, hay que tener en cuenta su comportamiento fundamental.
A pesar de que estos modelos son muy poderosos, su comportamiento es también muy sensible a las instrucciones. Por ello, la creación de instrucciones es una habilidad muy importante a desarrollar.
En la práctica, las instrucciones se utilizan para ajustar el comportamiento de un modelo para que realice la tarea prevista, pero no es una tarea fácil, y requiere experiencia e intuición para crearlas con éxito. De hecho, cada modelo se comporta de manera diferente, por lo que hay que prestar aún más atención a cómo aplicar los siguientes consejos.
Para los modelos GPT de Azure OpenAI, hay una API que toma el protagonismo en la prompt engineering: Chat Completion (compatible con ChaGPT y GPT-4).
Cada API requiere que los datos de entrada tengan un formato diferente, lo que también afecta al diseño general de la solicitud. Los modelos de Chat Completion están diseñados para tomar entradas dentro de una serie de diccionarios con formato y convertirlas en una transcripción específica similar a un chat.
Un ejemplo básico sería:
MODEL = «gpt-3.5-turbo»
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{«role»: «system», «content»: «You are a helpful assistant.»},
{«role»: «user», «content»: «Knock knock.»},
{«role»: «assistant», «content»: «Who’s there?»},
{«role»: «user», «content»: «Orange.»},
],
temperature=0,
)
Aunque técnicamente los modelos ChatGPT se pueden usar con cualquiera de las dos API, la más recomendable sería la de Chat Completion. De hecho, aunque se use este tipo de ingeniería rápida de forma eficaz, es necesario validar las respuestas que generan estos modelos LLM.
Resumimos las opciones más importantes para poner en marcha tu proyecto.
Es el mensaje aparece al comienzo de la solicitud, y se usa para preparar el modelo con instrucciones o información relevante para cada caso de uso. Se puede usar este mensaje para describir la personalidad del asistente, definir lo que el modelo debería o no responder, así como definir el formato de las respuestas.
Un mensaje del sistema bien diseñado aumenta la probabilidad de un determinado resultado, pero puede haber algún error en la respuesta. De hecho, un detalle importante es que si al modelo se le indica que responda “No sé” si no está seguro de la respuesta, no se garantiza que se cumplirá la solicitud.
Una de las mejores formas para adaptar los modelos de lenguaje a nuevas tareas es usar el aprendizaje de pocos intentos. Esta opción proporciona ejemplos de entrenamiento para dar contexto adicional al modelo.
Cuando se usa la API Chat Completion, aparece este tipo de mensajes entre el usuario y el asistente. Así se puede preparar al modelo para responder de cierta manera, imitar comportamientos concretos y generar respuestas a preguntas comunes.
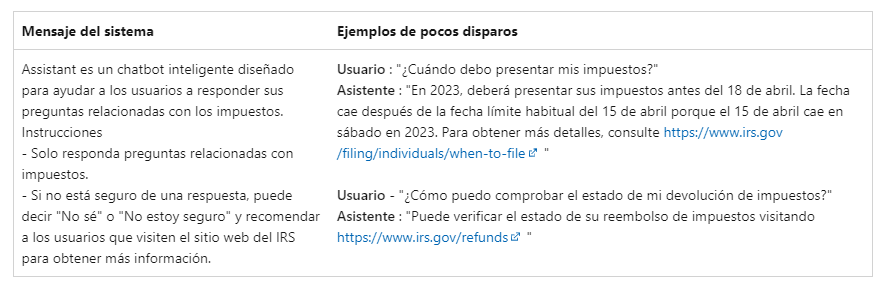
Aunque la API Chat Completion está optimizada para funcionar con conversaciones, también se puede usar para escenarios que no sean de chat. Por ejemplo, se puede usar para analizar opiniones de reseñas, consultas, etc. y sacar el grado de satisfacción o descontento de un usuario.
Estos escenarios son el momento perfecto para utilizar Copilot (para Windows u Office 365), pues tendrás a tu disposición un chat mucho más potente que el normal. Se utiliza habitualmente para usar un chat a modo de asistente al que darle órdenes para que ejecute acciones (sumarice un trozo de texto, haga una presentación de Power Point a partir de un hilo de emails, etc.).
Una vez que tengas claro todo lo anterior, es momento de poner en marcha tu proyecto. Si quieres hacerlo de forma exitosa, te recomendamos lo siguiente:
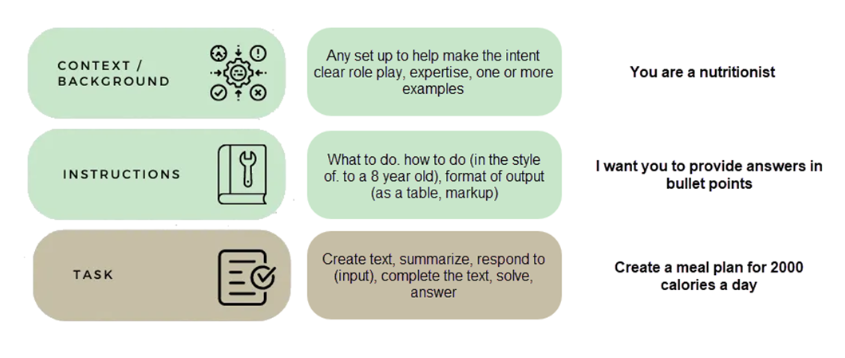
Siguiendo los pasos anteriores, podrás conseguir un modelo mucho más eficiente. Te dejamos un ejemplo básico de prompt sencillo con un contexto, unas instrucciones y la tarea a realizar.
ChatGPT y los servicios de OpenAI están cambiando la forma en la que se están y se van a hacer los negocios. Te hemos explicado cómo sacar partido a las técnicas de prompt engineering, pero debes prestar mucha atención a la seguridad, el gobierno y la supervisión de los datos que introduzcas.
Contar con una buena estrategia a la hora de adoptar este servicio es fundamental para conseguir buenos resultados y grandes beneficios en cuanto a creatividad, eficiencia, innovación y toma de decisiones.
Desde Plain Concepts te ofrecemos un Framework de OpenAI único en el que aseguramos su correcta implantación, mejorando la eficacia de tus procesos, así como el aumento de la seguridad empresarial crítica, a la par que satisfacer las necesidades de producción.
Te acompañaremos y ayudaremos a acelerar tu viaje por la IA generativa en todas sus fases, estableciendo juntos una base sólida para que aproveches todo su potencial en tu organización, encontrando los mejores casos de uso y creando nuevas soluciones empresariales adaptadas a ti.
Si quieres descubrir cómo podemos ayudarte a mejorar tu negocio, no dudes en ponerte en contacto con nosotros. ¡Saca el máximo partido de la IA generativa!
Elena Canorea
Communications Lead
