
Elena Canorea
Communications Lead
GPT models, developed by OpenAI, have positioned themselves as one of the engines of artificial intelligence and Natural Language Processing (NPL). Their capabilities to create human-like code and text have made them one of the great revolutions of the moment.
As Azure OpenAI specialists, we have compiled some of the most important advanced techniques in prompt design and prompt engineering for the APIs that GPT models rely on. Read on!
The GPT-3, GPT-3.5, and GPT-4 models are instruction-based. The user interacts with the model by entering a text directive, to which the model responds by completing the text.
Like all other generative language models, GPT models attempt to reproduce the next set of words that are most likely to follow the previous text as if it were a human typing it. As more complex cues are developed, their fundamental behavior needs to be taken into account.
Although these models are very powerful, their behavior is also very sensitive to instructions. Therefore, the creation of instructions is a very important skill to develop.
In practice, instructions are used to adjust the behavior of a model to perform the intended task, but this is not an easy task and requires experience and intuition to create them successfully. In fact, each model behaves differently, so even more attention needs to be paid to how to apply the following tips.
For Azure OpenAI GPT models, one API takes center stage in prompt engineering: Chat Completion (compatible with ChaGPT and GPT-4).
Each API requires the input data to be in a different format, which also affects the overall design of the request. Chat Completion models are designed to take inputs from within a series of formatted dictionaries and convert them into a specific chat-like transcript.
A basic example would be:
MODEL = “gpt-3.5-turbo”
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{“role”: “system”, “content”: “You are a helpful assistant.”},
{“role”: “user”, “content”: “Knock knock.”},
{“role”: “assistant”, “content”: “Who’s there?”},
{“role”: “user”, “content”: “Orange.”},
],
temperature=0,
)
Although, technically, ChatGPT models can be used with either of the two APIs, the Chat Completion API is the most recommended. In fact, even if this type of rapid engineering is used effectively, validating the responses generated by these LLM models is necessary.
We summarise the most important options for getting your project off the ground.
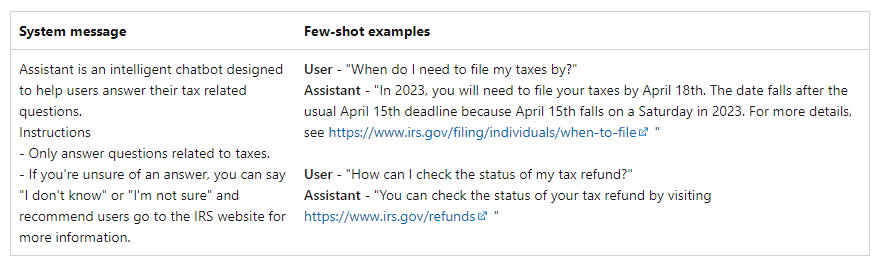
This is the message that appears at the beginning of the request and is used to prepare the model with instructions or information relevant to each use case. This message can be used to describe the assistant’s personality, define what the model should or should not respond to, and define the response format.
A well-designed system message increases the probability of a certain outcome, but there may be some error in the response. Indeed, an important detail is that if the model is instructed to answer “I don’t know” if it is unsure of the answer, there is no guarantee that the request will be fulfilled.
One of the best ways to adapt language models to new tasks is to use trial-and-error learning. This option provides training examples to give additional context to the model.
When using the Chat Completion API, such messages appear between the user and the assistant. This can prepare the model to respond in a certain way, mimic specific behaviors, and generate answers to common questions.
Although the Chat Completion API is optimized to work with conversations, it can also be used for non-chat scenarios. For example, it can be used to analyze feedback on reviews, queries, etc., and extract the degree of satisfaction or dissatisfaction of a user.
These scenarios are the perfect time to use Copilot (for Windows or Office 365), as you will have a much more powerful chat at your disposal than normal. It is commonly used to use a chat as an assistant to give orders to execute actions (summarise a piece of text, make a PowerPoint presentation from an email thread, etc.).
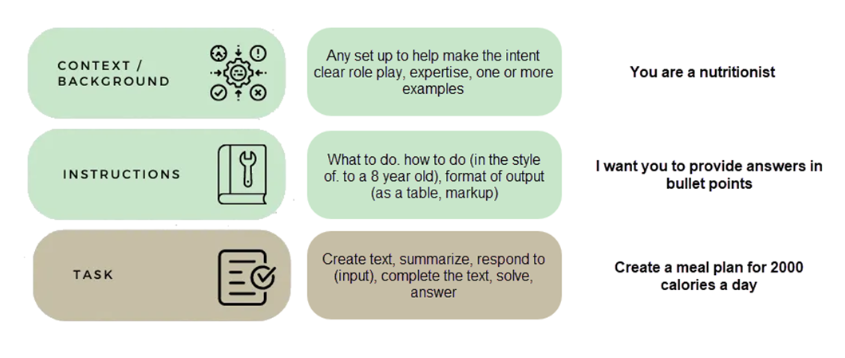
Once you are clear on all of the above, it is time to get your project off the ground. If you want to do this successfully, we recommend the following:
You can achieve a much more efficient model by following the steps above. Here is a basic example of a simple prompt with context, instructions and the task to be performed.
ChatGPT and OpenAI services are changing how business is and will be done. We have explained how to take advantage of prompt engineering techniques, but you need to pay close attention to security, governance, and monitoring of the data you enter.
Having a good strategy when adopting this service is essential to achieve good results and great benefits in terms of creativity, efficiency, innovation, and decision-making.
At Plain Concepts, we offer you a unique OpenAI Framework in which we ensure its correct implementation, improving the efficiency of your processes, as well as increasing critical business security while meeting production needs.
We will accompany you and help you accelerate your journey through generative AI in all its phases, establishing together a solid foundation for you to leverage its full potential in your organization, find the best use cases, and create new business solutions tailored to you.
If you want to find out how we can help you improve your business, don’t hesitate to contact us. Get the most out of Generative AI!
Elena Canorea
Communications Lead
