

Javier Carnero
Research Manager at Plain Concepts
At Plain Concepts’ Research team, we’re used to exploring innovative solutions for our clients, and in many of those cases, artificial intelligence plays a key role. Time and again, we’ve seen that its large-scale adoption faces critical challenges when relying exclusively on the cloud—namely: high recurring costs, exposure of sensitive data, network latency, and real scalability limits in organizations with hundreds of users.
That’s why, over the past few months, we’ve been working with some of our clients on a new hybrid architecture that combines the best of cloud AI with the power of personal devices capable of running AI models locally. This approach leverages distributed compute capacity while reducing operational costs.
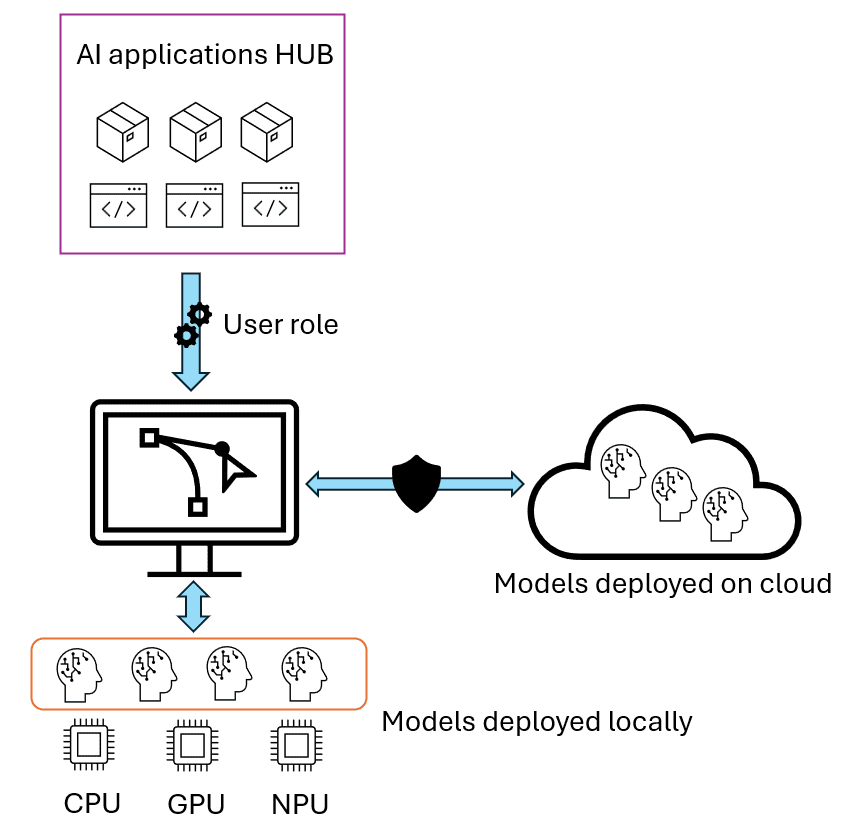
In this architecture, AI applications and models are first made available for deployment in a cloud HUB, which then performs selective deployment: heavy, complex models stay in the cloud for critical cases, while optimized models run locally for day-to-day use. Applications are then executed in a distributed way: each local device contributes inference power, removing centralized bottlenecks. Organizations also gain granular control: full governance over which data, models, and users access each resource.
Take, for example, a media company like MediaPro, which needs to process large volumes of video and audio for tasks such as transcription, automatic subtitling, or summarization. With a hybrid architecture, the most demanding models (say, advanced semantic analysis) can remain in the cloud and be accessible only to critical roles. Meanwhile, recurring, lighter tasks (like basic transcription or content classification) can run locally, leveraging the hardware acceleration of employees’ laptops. This enables scaling across the entire organization without incurring prohibitive costs or compromising data privacy.
This architecture is powered by Intel Core™ Ultra laptops with integrated NPUs (Neural Processing Units) and GPUs.
These laptops with built-in accelerators enable a new hybrid architecture that combines the best of both worlds: the raw power of the cloud for mission-critical workloads, and the efficiency of edge computing for everyday use cases.
This new way of thinking about hybrid computing requires personal devices capable of running AI models locally. To that end, at Plain Concepts we’ve started working with Intel Core™ Ultra laptops, taking advantage of their integrated accelerators: the NPU and the GPU.
The arrival of Intel Core™ Ultra processors marks a qualitative leap in the ability to run artificial intelligence on personal devices. These processors integrate a heterogeneous architecture that combines three specialized compute engines: CPU, GPU, and NPU, each optimized for different types of AI workloads.
The NPU (Neural Processing Unit) is a processor dedicated specifically to the efficient execution of AI models, particularly those that require recurring or background inferences. Its design focuses on maximizing energy efficiency, enabling sustained AI workloads without compromising device battery life. The NPU is ideal for tasks such as:
As Intel engineers put it, the NPU is the system’s “marathon runner”: it handles long-duration workloads sustainably, ensuring that a laptop’s battery lasts through a full workday—even in scenarios of intensive AI use.
The architecture of Intel Core Ultra processors distributes AI workloads according to their nature and performance requirements:
 |
 |
 |
|---|---|---|
| Fast Response | Performance Parallelism & Throughput | Dedicated Low Power AI Engine |
| Ideal for lightweight, single-inference, low-latency AI tasks | Ideal for AI-infused Media/3D/Render pipelines | Ideal for sustained AI and AI offload |
| P-core & E-core CPU Architecture | Xe2 GPU Architecture | NCEs, Neural Compute Engines |
| VNNI & AVX, AI Instructions | XMX, Xe Matrix Extension | Efficiency of matrix compute |
Intel Core™ Ultra laptops can run AI models locally using compatible frameworks such as OpenVINO, ONNX Runtime, Hugging Face Optimum Intel, and Azure Foundry Local.
Foundry Local runs language models directly on the client, automatically optimizing for CPU or GPU.
winget install Microsoft.FoundryLocal
foundry model run phi-3.5-mini
Foundry Local offers instant installation and transparent management with full privacy, though it’s currently in preview with a limited model catalog and without NPU support.
OpenVINO is the main toolkit for tapping into Intel’s NPU:
import openvino as ov
core = ov.Core()
core.available_devices # ['CPU', 'GPU', 'NPU']
Compression is key for efficient execution on local devices. OpenVINO with NNCF enables model reduction with minimal accuracy loss:
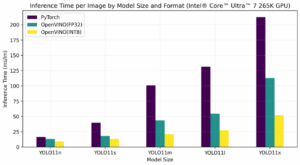
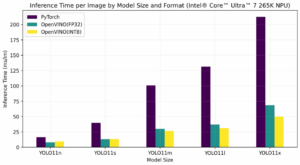
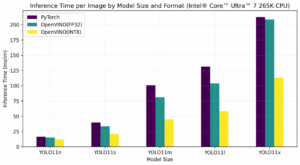
YOLOv8 optimization results:
Performance comparison by device:
| Device | Improvement with Optimization | Energy Efficiency |
|---|---|---|
| CPU | 2x faster | Standard |
| GPU | 4x faster | High |
| NPU | 3x faster | Maximum (~13W vs 20W) |
In the Research team, one of the core technologies we develop is Evergine, a graphics engine focused on 3D rendering for industrial applications. A common requirement in our work is integrating AI models into Evergine applications to achieve a deeper understanding of the environment, improving both interaction and the visualization of complex data.
As a proof of concept to test the capabilities of Intel Core Ultra laptops, we developed a photorealistic 3D environment using Gaussian Splatting to render a living room in real time, while simultaneously integrating an object detection model to identify and classify elements in the scene on the fly.
As the user navigates the environment, the GPU handles the rendering, while the NPU runs the object detection model in parallel. This enables faster, more energy-efficient identification and classification of objects—improving both runtime performance and power consumption—all without leaving the local device.


Intel Core Ultra laptops make it possible to run enterprise-grade virtual assistants with RAG (Retrieval-Augmented Generation) fully on-device, distributing workloads across the different accelerators:
Distributing workloads across the accelerators locally provides higher energy efficiency, since the NPU consumes ~13W compared to ~20W for CPU/GPU.
WebNN allows AI models to run directly inside web applications using hardware acceleration, with no extra installations. This enables instant web-based deployments, complete privacy (local processing), and automatic optimization based on the available hardware.
Examples include:
Image generation (Stable Diffusion Turbo on GPU):
Speech transcription (Whisper on NPU):
Image segmentation (Segment Anything):
Gimp integrates AI plugins that leverage Intel accelerators for advanced tasks. These plugins allow you to dynamically select the accelerator (CPU/GPU/NPU) depending on the workload.
Currently, three plugins are available:
The hybrid AI architecture powered by Intel AI PCs delivers clear, measurable benefits:
| Concept | Cloud Execution | Local Execution (Intel Core Ultra) |
|---|---|---|
| Usage cost | Variable (per token/hour) | Zero (included in the device) |
| Response latency | High (network + backend) | Low (on-device) |
| Monthly total cost (100 users) | €1,500–3,000 | €0–100 (support/IT) |
| Connectivity dependency | Critical | Optional |
The history of computing is marked by paradigm shifts. The arrival of the personal computer democratized technology. Today, AI is undergoing a similar transition: from the cloud to the endpoint—to the personal device.
Intel Core Ultra laptops with NPUs represent this shift, delivering:
Companies can now build a distributed, sustainable, and cost-effective AI model by combining the power of the cloud with the efficiency of the edge.
We are entering a new era of artificial intelligence, where innovation will depend on the ability to run AI where the data is actually generated and used: on the user’s own device.
Author’s Note: Part of the study and experiments that formed the basis of this article were presented in a technical talk at dotNET 2025 Madrid, co-delivered with Ana Escobar (ana.escobar.acunas@intel.com).
Many of the videos, demos, and data included in this work would not have been possible without Ana’s invaluable collaboration and expertise, for which I am especially grateful.
Javier Carnero
Research Manager at Plain Concepts