
Rafael Caro Fernández
Ingeniero de Software - Full Stack Developer - Plain Concepts
Introduction
In recent years, artificial intelligence has made a huge leap in both scope and applications. Since the arrival of ChatGPT (now essential in both work and daily life) AI has evolved from generating text, to creating images, and more recently, to producing videos with amazing visual quality.
Now it has gone even further: in the past few months, we have moved from generating videos to building whole worlds that can be visited, explored, and even interacted with in real time. Now we are not only speaking about images that could start to move, but about synthetic universes generated instantly from a text prompt or even a single image. These advances mark the beginning of a new era in which AI not only describes or represents, but also works as a world engine, being able to keep physics, memory and story during the experience.
Some of the best examples of this new stage are Genie 3, made by Google DeepMind, and Mirage 2, from Dynamics Labs. Both systems can create interactive worlds that people can explore as if they were playing a videogame and allows the player to change it freely by using extra text prompts. Doing all this without relying on any game engine, predefined structure or underlying code, but instead directly through neural networks that predict every pixel in response to the user’s inputs and interaction history.
A few weeks ago, Google surprised the world with a model capable of generating a wide variety of interactive environments. According to its website, all it takes is a prompt for Genie 3 to build dynamic scenarios that can be explored in real time, producing coherent experiences lasting several minutes, at 24 frames per second and with a resolution of 720p.
One of the most impressive aspects of this model is its ability to maintain consistency over time (it’s “memory”). The actions performed by the user that affect the world are preserved throughout the whole experience, as can be seen in the videos published by Google where, for instance, the user paints parts of a wall.
Genie 3 Video: The paint in the wall is kept (original)
As an emerging technology, Genie 3 still has limitations. The range of actions available to the user is limited, it cannot simulate accurately real-world locations, text representation is restricted, and the duration of the interaction is capped to just a few minutes.
Nowadays, this model is not available for direct testing, but only through videos released by Google. However, other systems are already beginning to appear that can be tried out, as we will see in the next case.
Mirage 2, developed by Dynamics Labs, generates its interactive worlds from existing images. All it takes is uploading an image and a text prompt (which can even be auto-generated) for the model to transform those elements into an explorable environment, allowing users to walk through it as if they were immersed in a video game.
This model can indeed be tested directly through its website.
The one-minute trials work quite well: you can move, jump, and add events via prompts, providing an immediate interactive experience.
According to Dynamics Labs’ website, Mirage 2 promises interaction of over 10 minutes with a latency of 200ms, and -most surprisingly- it could run on a consumer-grade GPU, making it accessible to everyday users.
We can embody the Infanta Margarita, although visual stabilidty begins to degrade shortly after starting the experience.
It has some limitations, like that movements do not always match the user’s commands, unexpected actions may happen, and visual stability is limited because the world’s “memory” does not last long.
These recent models represent a significant leap in quality, but they did not emerge out of nowhere. To understand their relevance, it is useful to look back and see how world simulation has evolved. Initially, with traditional video game engines like Unity or industry-oriented engines such as Evergine, physics were simulated and every object, environment and action had to be programmed manually. Later, the first attempts to apply generative AI emerged, aiming to automate part of the process.
In 2018, World Models, by David Ha and Jürgen Schmidhuber introduced a key idea: training AI agents in neural networks generated environments rather than in real-world settings or traditional simulations. This allowed agents to learn faster, training directly within an internal model of the world. In practice, the agent no longer needed to interact with an external system. Instead, it could train within its own “imagination”, predicting what could happen in the next frames and acting accordingly.
In the training of a “normal” AI, the AI performs actions on a simulation (it could interact with a system, such a video game or other type of software) trying to predict, based on its memory, what will happen in the next frames and acting accordingly:
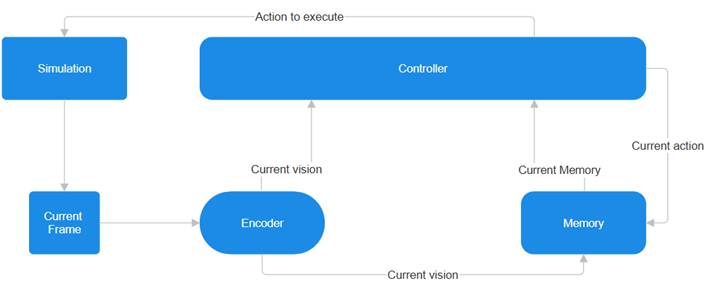
With the concept of world simulation, the agent does not need to be connected to a real system on which to perform actions. Instead, the actions are executed directly within the agent’s own memory, which “imagines” what the next action in the world would be.
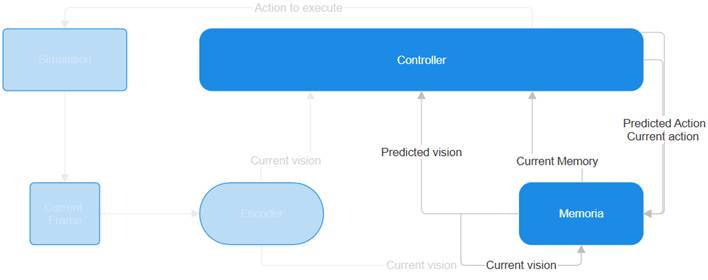
This concept was used as the foundation for new world models which could maintain a certain temporal coherence and memory, albeit still limited. In parallel, video generation models such as Sora from OpenAI and Kling from Kuaishou emerged, extending the duration, resolution and complexity of the generated scenes.
These models, trained with massive amounts of video, showed remarkable emergent capabilities: they were able to simulate aspects of people, animals and physical-world environments. And those properties were not explicitly programmed using 3D models or defined objects but rather emerged directly from large-scale training. This finding opened a promising path towards the creation of more realistic digital and physical simulators.
Nevertheless, they still have significant limitations. They struggle to maintain physical laws in basic interactions (for instance, a cristal breaking or an object being eaten) and do not always consistently represent the consequences of actions. Even so, these advances are a clear indication of the potential for the future of world simulation.
Next iteration involved training generative Ais with video game footage, additionally adding user input as part of the training. This way, the AI emergently learned the meaning of each action (jumping, attacking, moving…) and, during world simulation, could calculate and alter the next frames based on what the player intended to do.
With this idea, GameNGen from OpenAI emerged. Considered the first video game engine operating only with neural networks in complex environments. Demonstrations show that it is possible tto play the classic DOOM at 20 frames per second on a TPU:
Following this, Decart developed Oasis. This world model for Minecraft is able to simulate the game’s physics, rules and graphics in real time from a single image. They even provide a playable demo that allows users to experiment with a Minecraft simulation for a few minutes:
Advances in the use of these world models for agent training have also been made, as in the case of GAIA-1 from Wayve. This is a proof of concept capable of generating a world model for autonomous driving. It helps systems anticipate and plan actions, spot potential dangers or hazards and explore different futures. Using these world models in driving could help autonomous systems understand human decisions better and make safer and more efficient choices in real-life situations.
These advances show how AI simulation has grown from early ideas and experiments to the first neural video game engines that can learn directly from gameplay. What started as simple, limited environment or copies of specific games is now moving toward more general world engines like Genie 3 or Mirage 2. These no longer depend on existing games or fixed rules, they create dynamics world from text or images instead. This opens the door to a new era where artificial intelligence does not just reproduce worlds but also creates and maintains them in real time.
These world engines open a wide horizon. Even today, in just the beginning, they already amaze us with their detail and quality. In the incoming years, they could become tools that change the way we work in many fields.
On one hand, Mirage 2 points to the future of entertainment. Imagine video games where the environment is not set in advance but are created in real time based on the player’s decisions. Worlds could be created and shared instantly with friends, stories could emerge from the player’s own actions, and each session could be unique.
On the other hand, Genie 3 focuses on training AI agents. With it, robots could be trained by using models of the real world, speeding up their training. Using images from their cameras and simple text prompts, they could act without needing specific programming. These world models would give the agents (robots and autonomous systems) a space to be trained and tested. This ability to “imagine” and learn in virtual worlds could become a key step for the next stage of artificial intelligence.
Ultimately, these advances bring us closer to Ais that learn like humans: building an internal model of the world from limited information and making decisions based on it. As Jay Wright Forrester, the father of system dynamics, said in 1971:
“The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system.”
Today, with tools like Genie 3 and Mirage2, these mental images of the world are starting to materialize like virtual worlds that we can explore, change, and learn from. Taking a first step towards a future where artificial intelligence can imagine, create and exists with us in dynamic worlds.
Rafael Caro Fernández
Ingeniero de Software - Full Stack Developer - Plain Concepts
