
Elena Canorea
Communications Lead
¿Has oído hablar sobre el paradigma de data mesh (malla de datos)? A continuación exploramos los principios que sustentan este planteamiento y cómo la arquitectura de Sidra Data Platform aprovecha los beneficios prometidos que estos principios pueden traer a las organizaciones
Hace unos días, se publicó un interesante artículo titulado “Data Mesh, principios y arquitectura lógica”. Este artículo se basa en la idea de que, a pesar de que los avances tecnológicos de la última década han abordado la escala del volumen y el procesamiento de datos, no han abordado la escala en otras dimensiones; como mantenerse al día con los cambios en el panorama de datos o la proliferación de fuentes de datos y casos de uso. El artículo sugiere que algunos principios aplicados con éxito a sistemas operativos, como el diseño basado en dominios o contextos acotados, pueden haber sido pasados por alto hasta ahora para plataformas de big data. A medida que hay más datos disponibles en todas partes, es más difícil consumirlos todos en un lugar bajo el control de una sola plataforma y propietario.
Se esboza una idea sobre los data lakes y data warehouses como centralizados, monolíticos y agnósticos de dominio, en definitiva, no se puede escalar. Se describen los diferentes modos de fallo e incluyen aspectos como la incapacidad de responder a nuevas fuentes de datos o la desconexión entre el equipo de ingeniería de datos y los equipos de desarrollo. Como tal, se introduce la idea de una malla de datos descentralizada en torno a cuatro principios clave:
Basado en estos principios, el objetivo de la malla de datos es crear una base para obtener valor de los datos analíticos a escala. Sidra Data Platform es una propuesta única y diferente que va mucho más allá de la definición de un data lake monolítico. Sidra permite un flujo de datos de extremo a extremo gobernado, modular y completamente escalable.
En este post, exploraremos cómo los principios arquitectónicos clave de Sidra se comparan con los principios expuestos recientemente sobre el paradigma de malla de datos. Exploramos cómo estos principios, o al menos sus beneficios asumidos, se pueden lograr a través de la Plataforma de Datos de Sidra, manteniendo al mismo tiempo las promesas de una gestión y gobernanza racionalizadas.
Este principio concluye que la respuesta a los silos de datos tradicionales de datos inalcanzables, no se resuelve mediante la creación de un solo equipo centralizado que posea y cure los datos de todos los dominios. Al igual que los principios de diseño impulsados por el dominio, la distribución de la responsabilidad sobre los datos debe corresponder a los equipos más cercanos a donde se generan realmente los datos.
Sidra Data Platform es compatible con este principio, en el sentido de que los aceleradores creados para descubrir y recuperar los datos se han diseñado en torno a una jerarquía de metadatos agnósticos (Proveedores, Entidades, Atributos), con la posibilidad de definir diferentes propietarios para cada proveedor de datos. Además, Sidra admite varias Unidades de Almacenamiento de Datos (DSUs), donde cada una incluye componentes independientes desplegables, incluyendo los elementos estructurales de almacenamiento y procesamiento.
El lago de datos real es, entonces, una colección de DSUs independientes, que pueden ayudar a resolver el cumplimiento, ubicación de datos y las limitaciones de separación o, simplemente, los requisitos de la organización. El modelo de seguridad y autorización granular para Sidra permite integrar estas capacidades con la estructura organizativa de la empresa.
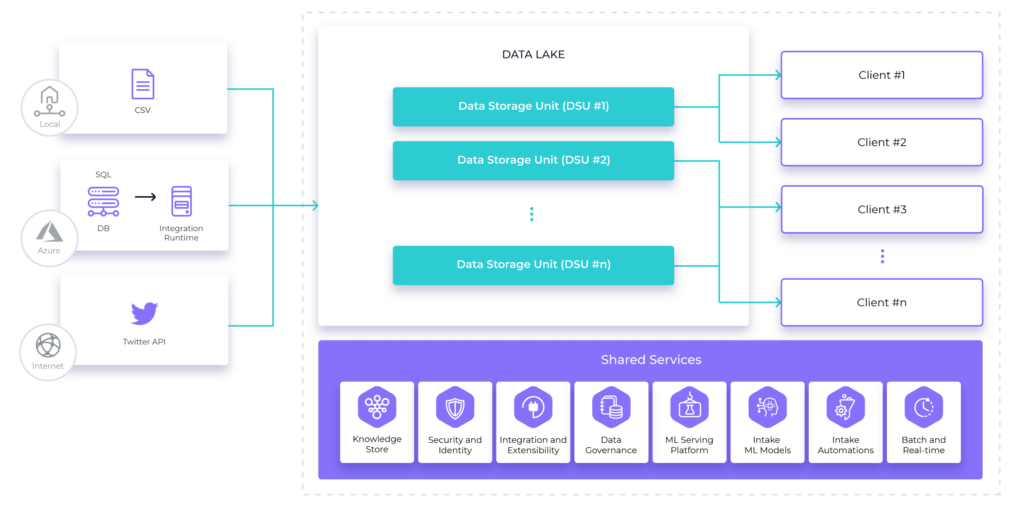
Desde el punto de vista de la transformación y explotación de datos específicos del negocio, el principio arquitectónico de Sidra Client Applications también está plenamente alineado con este principio. Se trata de los conjuntos independientes de servicios desplegables que transforman y hacen uso de los datos almacenados en el ESD para servir a un caso de negocio específico. La capa de procesamiento y persistencia de Aplicaciones Cliente se puede personalizar en innumerables escenarios, desde analíticas clásicas de BI hasta sandboxes de experimentación o tareas de minería del conocimiento. Las Aplicaciones Cliente hacen uso de su propia copia de datos del ESD (administrados y sincronizados transparentemente por la plataforma Sidra Core), su propio código y metadatos. Todo esto, enfatiza el principio de propiedad y evolución de los datos distribuidos.
Este principio deriva del alto coste tradicional de descubrir, confiar y utilizar datos de calidad. En un escenario descentralizado, los datos como producto se presentan como una forma de empaquetar código, infra, datos y metadatos para cada uno de los dominios de datos. El manejo de datos como un producto significa que hay necesidad de propiedad de productos de datos de dominio, que son responsables de un conjunto de métricas de éxito en torno al uso de sus datos, como con cualquier otro producto. Piensa en el tiempo de espera para el uso de datos, o índice de calidad de datos, por ejemplo. Lo mismo se aplica a los equipos de productos (ingenieros, analistas, científicos de datos), responsables de construir y mantener los productos de datos.
En Sidra, creemos firmemente en tener bases de infraestructura comunes, que se aprovechan centralmente en Sidra Core para proporcionar aceleradores y servicios comunes (canales preconfigurados, modelo de seguridad, sistema de eventos, API de gestión, monitor centralizado, etc.). Esto permite que cada Aplicación Cliente acepte la posibilidad de tener equipos trabajando en cada dominio (por ejemplo, cada Aplicación Cliente implementa una lógica de negocio de dominio de datos y sirve a uno o varios dominios), pero solo se centran en los detalles de negocio. Cada Aplicación Cliente representaría una unidad de código, infraestructura y metadatos y, al mismo tiempo, se beneficiaría del almacenamiento centralizado, el marco común de metadatos y linaje y las reglas comunes de optimización (almacenamiento optimizado).
Este enfoque modular de Aplicaciones Cliente también facilita la atribución de costes por dominio. El modelo común de autenticación y autorización de seguridad de Sidra permite una gestión descentralizada, pero totalmente controlada de los datos. Este enfoque nos permite adaptarnos rápidamente a nuevos casos de uso (por ejemplo, desde el BI tradicional a la minería del conocimiento), incluyendo casos de uso de experimentación pura, como Data Labs.
Adicionalmente, Sidra Data Catalogue incluye esta pieza centralizada requerida de descubrimiento de datos, documentación y linaje. Los usuarios y equipos de cada dominio tendrían permisos para acceder solo a ciertos datos de DSUs o proveedores, si fuera necesario, respetando así los límites organizacionales en torno a los dominios de datos de producto.
Construir, implementar y operar un producto de datos requiere habilidades e infraestructura especializadas. La infraestructura de datos de autoservicio, como principio de plataforma, requiere herramientas que ayuden a un desarrollador de productos de datos de dominio para crear, mantener y ejecutar productos de datos como una abstracción, lo que requiere un conocimiento menos especializado. Así, el autoservicio reduce las barreras de uso e innovación.
Una dimensión clave que ha ido creciendo con Sidra desde sus inicios es, precisamente, su capacidad de autoservicio. La arquitectura de Sidra ha estado pasando por un enfoque evolutivo para facilitar los aspectos de instalación, configuración y creación de nuevas integraciones entrantes (conectores de datos) y salientes (aplicaciones cliente).
Las capacidades actuales de autoservicio de Sidra se pueden organizar en conjuntos lógicos tales como:
Además de esto, los próximos lanzamientos de Sidra representarán un cambio cualitativo aún mayor, con un proceso más simplificado y fácil de usar para crear nuevos conectores de datos y Aplicaciones Cliente desde la interfaz web.
Para acabar, el cuarto principio se refiere al modelo de gobernanza que abarca la descentralización y la autosoberanía de dominio, mientras que sigue siendo interoperable a través de la estandarización global. Esta estandarización permite adherirse a un conjunto de reglas globales, que se aplican a todos los productos de datos y sus interfaces. Este principio, por supuesto, se basa, no sólo en la arquitectura, sino en una estructura organizativa de apoyo.
Hacer el paralelismo con Sidra requeriría repetir algunos de los puntos ya mencionados anteriormente, especialmente en torno al paradigma de Aplicaciones de Clientes y las capacidades y servicios transversales centrales, como el catálogo centralizado y los metadatos, modelo de seguridad y resto de servicios comunes (por ejemplo, la plataforma de servicio ML, la interfaz de usuario de gestión, la gestión de API). Una mención especial aquí al Hub de Integración, que aprovecha Service Bus para habilitar la mensajería entre Aplicaciones Cliente y Sidra Core o entre las Aplicaciones Cliente. Integration Hub permite una sincronización más profunda y permite una mayor composición de los casos de uso empresarial.
Todos los puntos tratados, demuestran que Sidra es, más allá de un Data Lake, una plataforma de datos completa y modular, además de ser una prueba de futuro.
Esperamos que haya disfrutado de este artículo. Si tiene alguna pregunta sobre los puntos anteriores, no dudes en ponerse en contacto con nosotros directamente en sidra@plainconcepts.com
Elena Canorea
Communications Lead
