
Elena Canorea
Communications Lead
During the last few years, a research effort has been made to automate the analysis of medical images used in the diagnostic-therapeutic cycle.
In modern medicine, making a diagnosis using images is invaluable. Computer tomography (CT) imaging and other modalities provide a non-invasive and effective means of delineating the subject’s anatomy.
Image segmentation has become a key process for the delineation of certain anatomical structures and other regions to assist and aid physicians in surgery, biopsies, and other clinical tests.
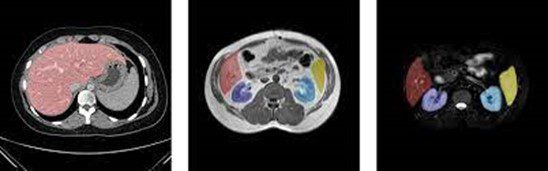
Example of organ segmentation
Over time, Artificial Intelligence techniques, and in particular the use of Deep Learning, have allowed the field of computer vision to advance rapidly in recent years. In this article, we show how we can use semantic segmentation techniques for organ detection in medical images.
Currently, convolutional neural networks have been used to solve different tasks within the domain of Computer Vision. The resolution of each of these tasks provides us with a different degree of understanding of the images.
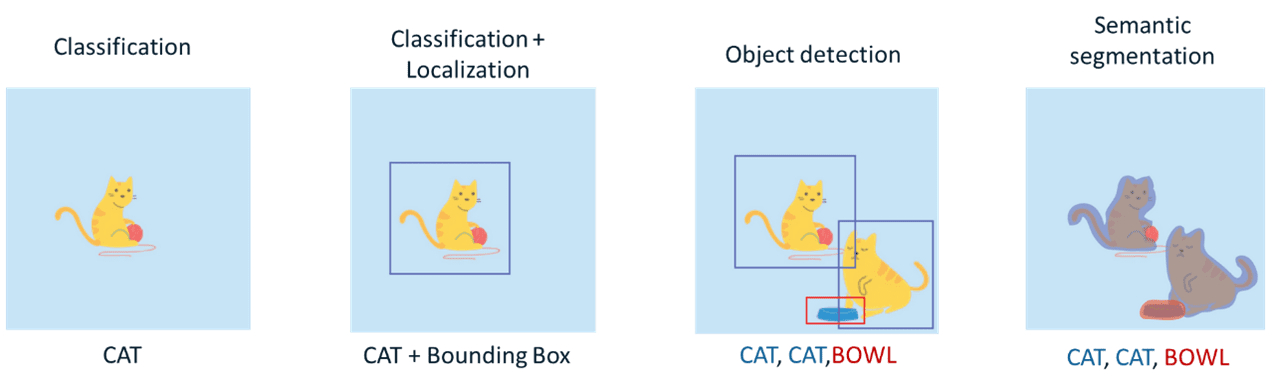
Types of Computer Vision tasks
As previously mentioned, in this case, we will focus on one of the most complex tasks in the field of computer vision: Semantic Segmentation. The goal of this task (within the field of images) is to label each pixel of an image with the corresponding class of what it is representing. Because we are performing prediction for each pixel in the image, this task is commonly referred to as dense prediction.
The performance of our model will largely depend on the quantity and quality of the data set. For this reason, the selection of the dataset is one of the most important processes within the workflow of Machine Learning projects.
As mentioned at the beginning of the article, the goal of our model is to detect organs (at the semantic segmentation level) from medical images of the abdomen.
Due to the sensitivity of this medical information, an anonymized dataset (CHAOS: Combined Healthy Abdominal Organ Segmentation) Dataset) has been used specifically for research topics within this area. This dataset is composed of several sources. In this case, we have focused on using a subset of data for the detection of the following organs: spleen, kidneys (left and right), and liver.
Throughout this section, we will discuss the most important aspects that have been conducted during our organ segmentation training process.
As our dataset consists of DICOM images, before launching the training process, it is necessary to process all our data and convert these images into an array of pixels. Once the array extraction is done, several transformations will be performed: affinity and image size reduction. Finally, the images are normalized in order to obtain a better performance during the training phase.
U-Net is a convolutional neural network architecture that was developed for biomedical image segmentation, therefore, we will rely on its base architecture for our model definitions. On this occasion, we have used some variants of the original topology to perform our training process: U-Net with (Resnet18) and U-Net++.
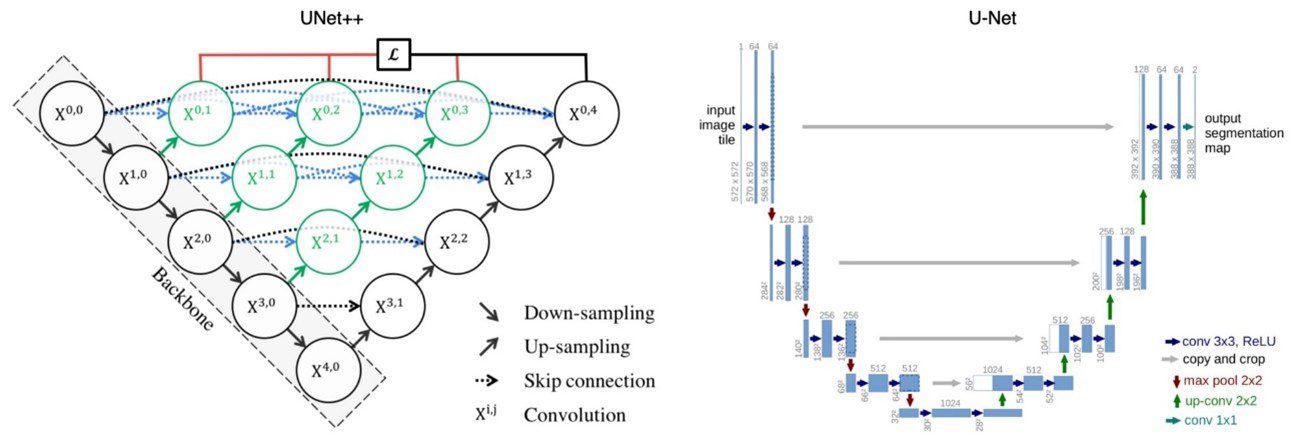
Topology of the models used
The loss function in the field of neural networks is a function that evaluates the deviation between the predictions made by the network and the real values of the observations used during the training process. The lower the result of this function, the more efficient the neural network is. The objective of training a neural network is to try to minimize this function as much as possible in order to minimize the deviation between the predicted value and the actual value.
One of the most commonly used loss functions in the case of image segmentation is the “dice” coefficient. This coefficient is used to determine the degree of overlap between the predicted mask and the labeled mask.
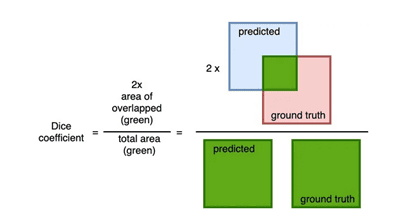
Calculation of the “dice” coefficient
The Dice coefficient has a range of values between [0,1] where 1 indicates a total overlap. Therefore, if we want to minimize this function as much as possible, the value of (1- Dice coefficient) can be used as a loss function.
In our case, the final loss function used for training is a combination of the Weighted Binary Cross-Entropy loss function and the Dice loss function.
In this section, we will discuss the results obtained during the training process.
The hyperparameters used in the training were the following:
As we can see in the following image, the Unet-Resnet model converges faster than the Unet++ model (this is due to the use of a model with pre-trained weights in the “encoder” layers and a smaller number of parameters).
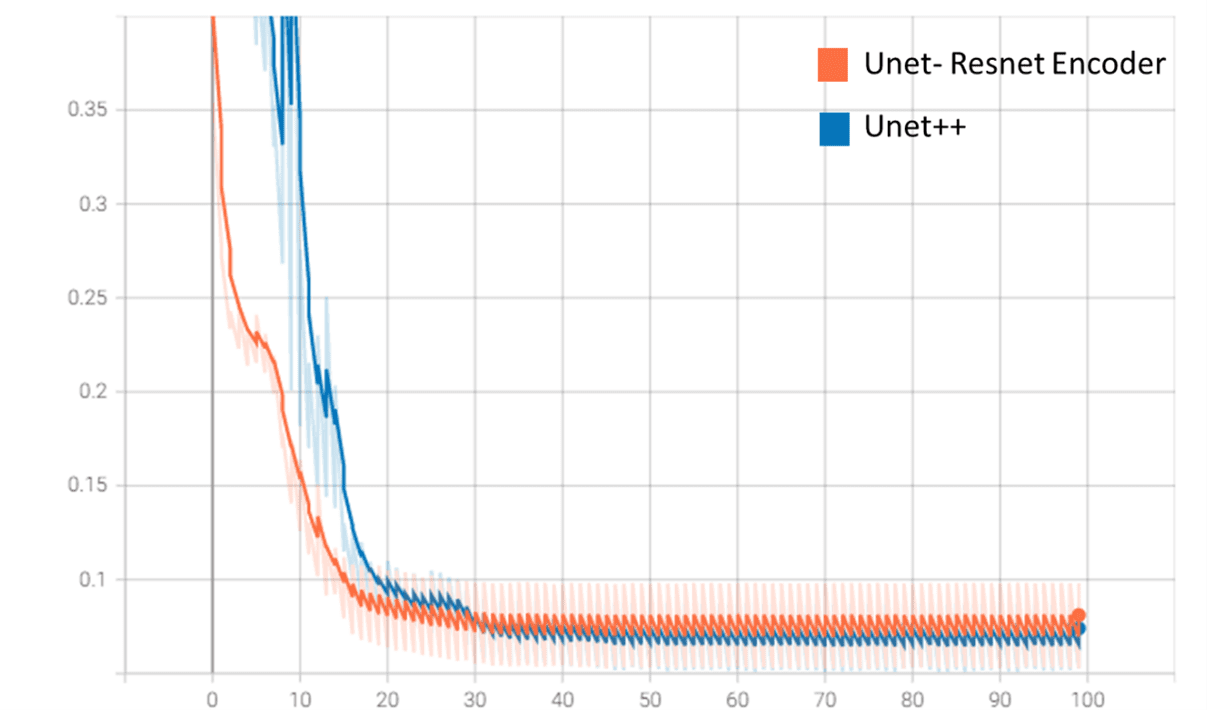
Loss function values (validation) on Tensorboard
On the other hand, although the Unet++ model performs better in validation (loss function “tells”), Unet-Resnet trains much faster and has a smaller size (70 MB vs. 500 MB for Unet++).
Several results of the model using the validation data set are shown below. Each example consists of the input image, the image labeled by the physician/specialist, and the prediction made by the model.
Color coding: Orange – Spleen, Yellow – Right Kidney, Brown – Left Kidney, Blue – Liver.
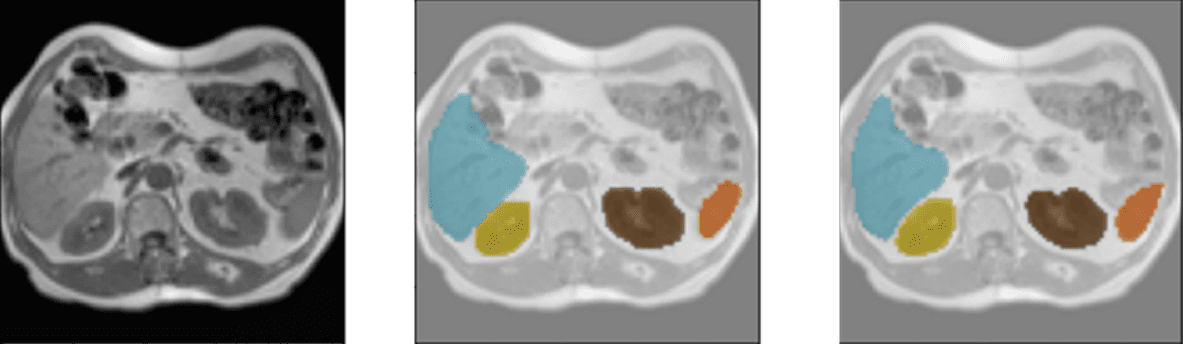
Detection of liver, spleen, and kidneys
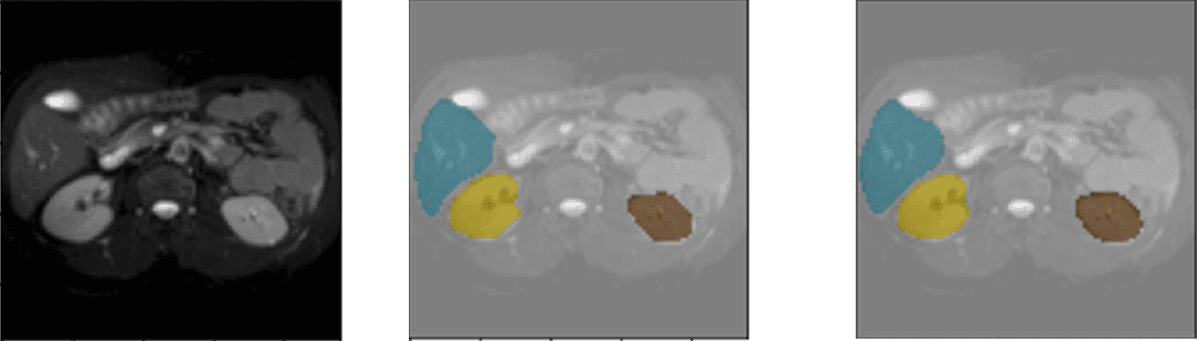
Liver and kidney screening
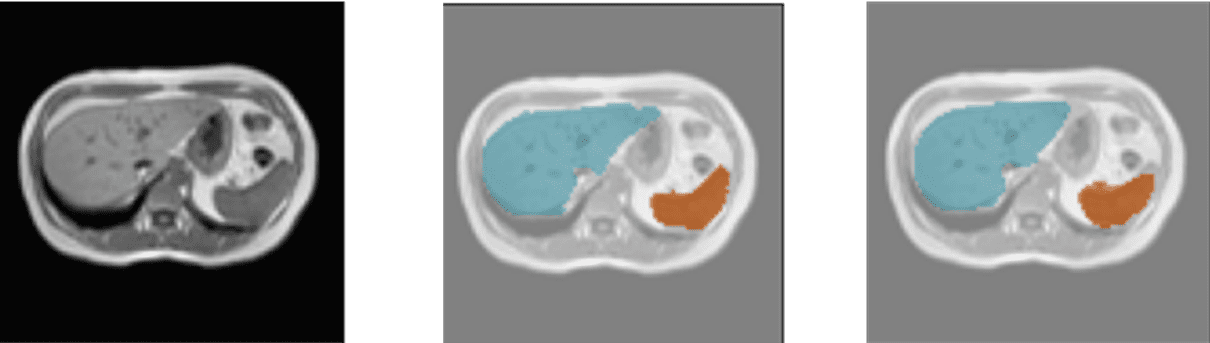
Liver and spleen detection
The use of Deep Learning techniques in medical imaging can help specialists in their decision-making when working on a diagnosis.
One of the first tasks that can facilitate the use of this type of techniques is the integration of the model in any of the hardware devices used by specialists to visualize or represent medical images (mobile devices, HoloLens, and computers). To carry out this process, it will be necessary to previously evaluate the performance of the model and apply different optimization techniques such as: “Pruning or quantization”. The application of these methods will ensure that our model can better adapt to the possible hardware limitations of the device.
As we have seen in this article, our model is able to detect organs from 2D medical images. As a possible future development, this model could be integrated into devices that allow interaction with a 3D representation of the abdomen.
The use of our model within these solutions will help to improve a variety of clinical tests. The system can show at all times where the organs are located and thus, be able to plan the optimal puncture that produces the least amount of damage to adjacent organs.
Elena Canorea
Communications Lead
