
Elena Canorea
Communications Lead
Have you heard about the data mesh paradigm? Here we explore the principles underpinning this approach and how Sidra Data Platform’s architecture leverages the promised benefits that these principles can bring to organizations.
A few days ago, an interesting article was published about Data Mesh principles and logical architecture. This article builds on the idea that, while technology advances of the past decade have addressed the scale of volume of data and data processing, they have failed to address scale in other dimensions, like keeping up with the changes in the data landscape or the proliferation of sources of data and use cases. It suggests that some principles applied successfully to operational systems, like domain driven design or bounded contexts, may have been overlooked so far for big data platforms. As more data become available everywhere, it is more difficult to consume them all in one place under the control of one single platform and owner.
The article outlines an idea about data lakes and data warehouses as being centralized, monolithic and domain agnostic, thus failing to scale. The different failure modes are outlined in this article and include aspects like the inability to respond to new data sources or the disconnect between the data engineering team and the source teams. As such, the idea of a decentralized data mesh is introduced around four key principles:
Based on these principles, the data mesh objective is to create a foundation for getting value from analytical data at scale. Sidra Data Platform is a unique proposition much beyond and different to the definition of a monolith data lake. Sidra allows a full end to end governed, modular, and fully scalable flow of data.
In this post, we explore how Sidra’s key architectural principles compare to the recently discussed principles exposed in the data mesh paradigm. We explore how these principles, or at least their assumed benefits, can be achieved through Sidra Data Platform while keeping the promises on streamlined management and governance.
This principle concludes that the response to the traditional data silos of unreachable data is not solved by creating a single, centralized team who owns and curates the data from all the domains. Similar to the domain driven design principles, the distribution of responsibility on data should map to the teams closest to where the data is actually generated.
Sidra Data Platform is compatible with this principle, in the sense that the accelerators built for discovering and retrieving the data have been designed around an agnostic metadata hierarchy (Providers, Entities, Attributes), with the possibility to define different owners for each data provider. Also, Sidra supports several Data Storage Units (DSUs), where each DSU includes independent deployable components, including the storage and processing structural elements.
The actual data lake is then a collection of independent DSUs, which can help solve compliance, data location and separation constraints or just organizational requirements. The security and granular authorization model for Sidra allows integrating these capabilities with the organizational structure of the company.
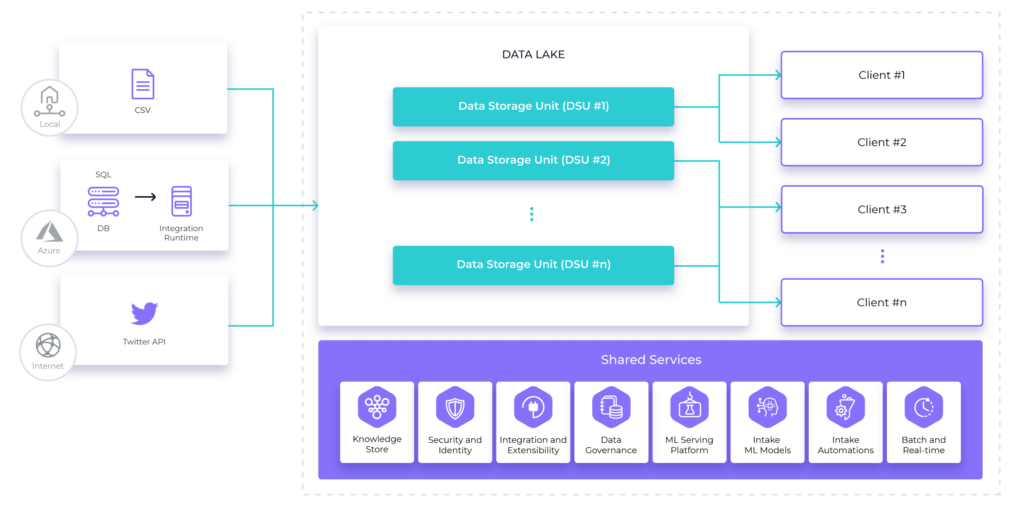
On the side of business-specific data transformation and exploitation, the architectural principle of Sidra Client Applications is fully aligned with this principle as well. Sidra Client Applications are the independent sets of deployable services that transform and make use of the data stored in the DSU to serve a specific business case. The processing and persistence layer of Client Applications can be personalized to a myriad of scenarios, from BI classical analytics to experimentation sandboxes or knowledge mining tasks. Client Applications make use of their own copy of the data from the DSU (managed and synchronized transparently by the Sidra Core platform), its own code and metadata. All this emphasizes the principle of distributed data ownership and evolution.
This principle stems from the traditional high cost of discovering, trusting and using quality data. In a decentralized scenario, data as a product is presented as a way of packaging code, infra, data and metadata for each of the data domains. Handling data as a product means that there is need for domain data product owners, who are responsible for a set of success metrics around the usage of their data, as with any other product. Think about lead time for the usage of data, or data quality index, for example. The same applies to the product teams (engineers, analysts, data scientists), responsible for building and maintaining the data products.
In Sidra, we fully believe in having common infrastructure foundations, that are leveraged centrally in Sidra Core to provide common accelerators and services (preconfigured pipelines, security model, event system, management APIs, centralized monitoring, etc.). This allows having each Client Application embrace the possibility to have dedicated teams working on each domain (for example, each Client Application implementing one data domain business logic and serving one or multiple other domains), but just focus on the business-specifics. Each Client Application would represent a unit of code, infrastructure, and metadata, and at the same time benefit from centralized storage, common metadata and lineage framework, and common optimization rules (optimized storage).
This modular approach to Client Applications also makes cost attribution per domain easy. The common security authentication and authorization model of Sidra allows a decentralized, yet fully controlled management of data. This approach allows us to adapt fast to new use cases (e.g., from traditional BI to knowledge mining), including pure experimentation use cases, like Data Labs.
Additionally, Sidra Data Catalogue includes this required centralized piece of data discoverability, documentation, and lineage. Users and teams for each domain would be given permissions to access only certain DSUs or provider data if needed, thus respecting organizational boundaries around product data domains.
Building, deploying and operating a data product requires specialized skills and infrastructure. The self-serve data infrastructure as a platform principle requires tooling that aids a domain data product developer to create, maintain and run data products as an abstraction, requiring less specialized knowledge. Thus, self-service lowers the barriers of usage and innovation.
One key dimension that has been growing with Sidra since its inception is precisely its self-service capabilities. The architecture of Sidra has been going through an evolutionary approach to facilitate the aspects of installing, setting up and creating new inbound (data connectors) and outbound (Client Applications) integrations.
Current self-service capabilities of Sidra can be organized in logical sets such as:
On top of this, Sidra’s upcoming releases will represent an even bigger qualitative change, with a more streamlined and user-friendly process for creating new data connectors and Client Applications from the web interface.
Finally, the fourth principle refers to the governance model that embraces decentralization and domain self-sovereignty, while it keeps being interoperable through global standardization. This standardization allows adhering to a set of global rules, that are applied to all data products and their interfaces. This principle, of course, relies not only on architecture but on a supportive organizational structure.
Making the parallelism with Sidra would require repeating some of the already mentioned points above, especially around the Client Applications paradigm and the central transversal capabilities and services, like the centralized catalogue and metadata, security model and rest of common services (e.g., ML service platform, Management UI, API management). One special mention here to the Integration Hub, which leverages Service Bus to enable messaging between Client Applications and Sidra Core or among Client Applications. Integration Hub allows a deeper synchronization and enables further composition of business use cases.
All the covered points demonstrate that Sidra is, beyond a Data Lake, a comprehensive Data Platform that is modular and future-proof.
We hope you enjoyed this article. If you have any questions on the points above, feel free to reach out to us directly at sidra@plainconcepts.com
Elena Canorea
Communications Lead
