
Elena Canorea
Communications Lead
This release comes with a lot of improvement features on several key modules of Sidra, especially on the data ingestion and the ML serving space. The data intake improvements have also been taken to the UI connectors (plugin) model, so the new versions of the connectors include multiple performance and functional improvements.
The plugin approach used for connectors (configuration of new data intake processes) has also been adapted to the Client Application space. This way, with this model, any new Client Application in Sidra that is developed following this plugin package approach can be easily created and deployed from a web UI.
On top of that, this release comes with important features around the operability of the platform, both from the web perspective, but also from the perspective of other operational tools, like the automation of API services monitoring and restarts.
With this release, we are also pleased to announce our new Sidra ideas portal, where you can have a place to share and vote ideas for Sidra.
A big part of the engineering effort in this release has been dedicated to review and update important functional and performance enhancements on data intake pipelines. These new features have been introduced in order to support certain new scenarios, as well as to substantially improve the performance of the data intake processes.
Next is a list with all the updates included in this feature:
NeedReload flag to True. However, this was not enough to force a reload until the field EnableReload was set to 1 in the EntityDeltaLoad table. This feature now includes an improvement by which a new AutomaticReload property is used and populated in the AdditionalProperties Entity field. This way, when this field AutomaticReload is true, and NeedReload is true, a condition is triggered to reload the pipeline, no matter the value of EnableReload.You can see more information about these fields in the EntityDeltaLoad and SQL Server incremental load mechanism documentation pages.In the previous release of Sidra, 2021.R1, data connectors UI feature was launched to simplify the configuration of new data intake processes via Sidra Web. Although using the term connectors to refer to the different programs to connect to the data source systems (e.g. SQL Server, Azure SQL database), internally such programs are packaged in a plugin model. For creating and configuring data intake processes, we use plugins of type connector. Such plugins are code assemblies that get downloaded, installed, and executed from the Web UI.
A very important advantage of plugins is that their release lifecycle can be decoupled from Sidra main releases life-cycle, which increases delivery speed for new plugins and reduces dependencies. You can see more details about the plugin approach in Sidra connectors documentation. With 2021.R2 the whole plugin management and architecture has been adapted to allow the deployment of Client Applications from the Web. In this case, the plugins used are of type Client Application.
This is a major achievement of this release. Along with subsequent versions of Sidra, we plan to announce and release new plugins of type Client Application. We plan to migrate existing Client Application templates with this new plugin model, so that the deployment (from a given template) of a Sidra Client Application can be performed just by filling out a set of UI wizard steps. The same approach is ready to be followed as well for implementing future new customer Sidra Client Applications.
In addition to this, Sidra Web now incorporates a Client Application detail page that exposes the metadata information about Client Applications. Clicking on each Client Application, a Client Application detail page is opened, which displays metadata fields like the Data Catalog for Providers and Entities: short description, business owner and a detailed description field allowing markdown edition.
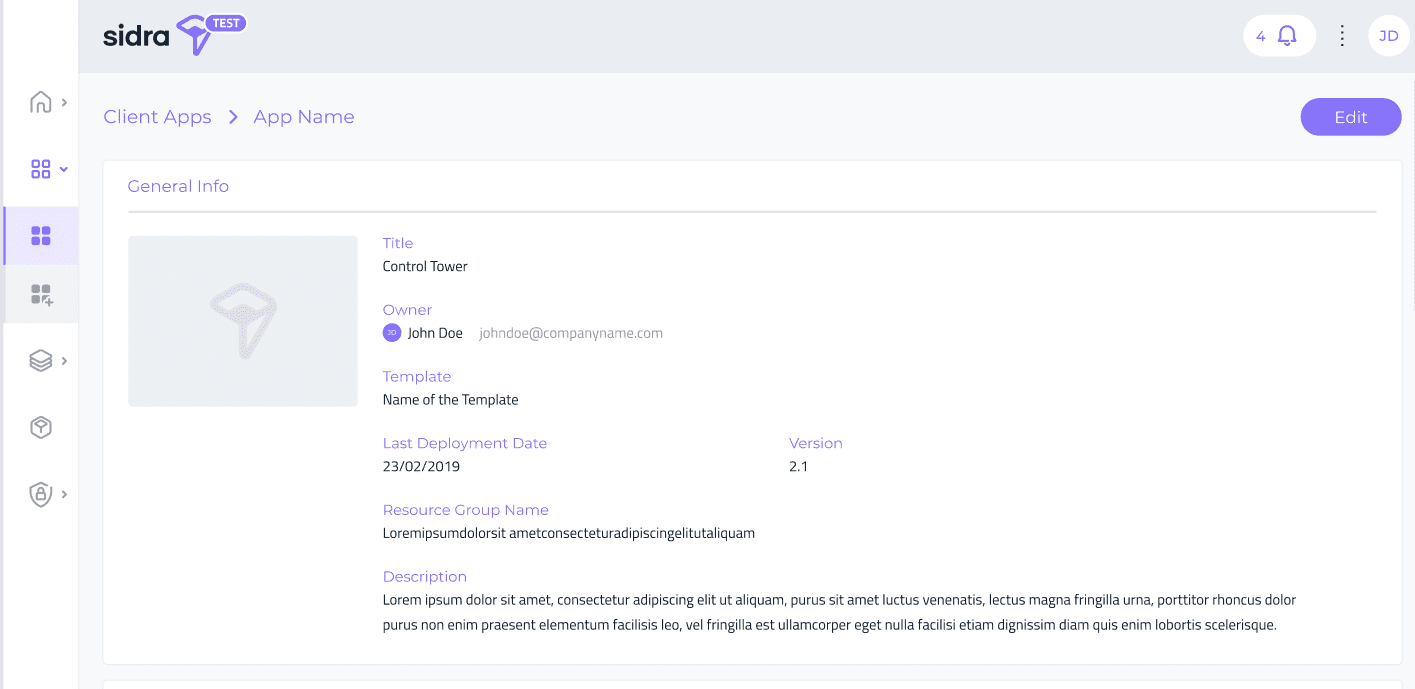
This view will be the entry point towards adding, in subsequent releases, more operational details and actions on Client Applications.
Sidra architecture relies on the concept of Data Storage Unit (DSU) as the atomic infrastructure unit for data processing (data intake, data storage, data transformation, data indexing and data ingestion) in Sidra. Each Data Storage Unit allows separation of concerns and even regional data segregation if needed.
After releasing Sidra CLI tool for installation and deployment of Sidra, there was a pending requirement to migrate the new deployment process to separately being able to install a second or subsequent DSUs. This feature incorporates a specific deployment script and process for installing additional DSUs on top of the default DSU which comes with any Sidra installation. This feature is subject to the availability of dependant Data Storage Unit Azure services in each region, and this includes Databricks service regional availability.
This feature allows decoupling plugin development and release cycles, both for connectors and for Client Applications, by managing the visibility of any plugin and plugin version at each customer and Sidra installation level. Through this feature, it is now possible for customers to limit the visibility of plugins and plugin versions to certain Sidra installations. This enables scenarios of early testing and validation of new plugins being developed.
The TypeTranslation table stores type mapping and transformation rules for the different stages of the Attributes processing when data sources are configured and ingested in Sidra. You can see more information about these tables in Data ingestion documentation and About Sidra connectors pages.
The use of such table has been extended to host all types of type mapping and transformation rules between database source systems, ADF and Databricks. Each plugin now handles the configuration and versioning of a set of type translation rules. These type translation rules are then applied during the data extraction and ingestion processes.
Each plugin persists the needed data types translations and rules when being installed. The responsibility to populate this TypeTranslation table also lies now on each specific plugin, instead of being centralized in Sidra Core.
This means that the different type mappings for each connector plugin are now completely decoupled from Sidra Core release process and tied solely to the corresponding plugin release process.
As part of the operational hardening of the platform, we have incorporated a set of enhancements related to creating and handling Databricks tables in certain scenarios. These are the set of changes included as part of this optimization:
<database>_<schema>_<table name>#,*, etc. These names are transformed into the _ character when moving to Databricks. This means that many of these Attributes may end up having the same name. In order to avoid this, the change consists of appending a number suffix to the names of the columns in Databricks, e.g., _1, _2, etc., so there is no duplication of column names.Databricks runtime version in Sidra has been updated to 8.3. This comes with interesting updates and features, like Python 3.8, faster cluster startup times, many performance improvements and as JSON operators in SQL, among others.
We have performed an extensive review on Sidra’s ML Model serving framework and capabilities, to adapt to the fast changing landscape and technical evolution of the key services underneath this module. These are the main updates performed as part of this review: – Updated Python Version to 8.3.3. – Updated MLFlow to 1.18. – Updated AzureML components to 1.32. – Updated the ML Deployment notebooks to accommodate to the breaking changes in AzureML and MLFlow updates. – Updated the ML tutorial and code examples.
We have implemented our first version of an Oracle pipeline template following Sidra design guidelines. This data intake process has not been implemented yet as a plugin of type connector, but this is planned for the next release of Sidra. The main characteristics of this Oracle pipeline are the following ones:
Data intake pipelines for database source systems (e.g. SQL, DB2) included a tables exclusion parameter in order to configure a list of objects to exclude from the metadata extraction pipeline. With this Sidra release, we have incorporated an enhanced object selection mechanism, through which users can choose a list of objects to include, or a list of objects to exclude. By default, inclusion mode with all objects is configured. This change has been taken to existing database pipelines and plugins: SQL Server, Azure SQL, DB2, plus the Oracle pipelines. Internally, objects to include or exclude are persisted on the LoadRestrictionObject tables in Sidra Core database. You can see documentation on LoadRestrictions and About connectors feature documentation.
Sidra now incorporates support for DB2 in the connectors framework model. This allows to set up a data intake process from DB2 database source systems just by following a few-steps configuration wizard. This version of the plugin comes with Sidra-backed incremental load mechanism.
Sidra incorporates an out of the box capability to run different operational runbooks to automate the periodic health monitoring of API services and attempt automatic restart in case they are down. This is achieved via Azure automation account implementation.
This release comes with a new version of the SQL Server metadata extraction pipeline, which has also been released as a new version of the SQL Server connector plugin. This version allows to configure the metadata extraction from multiple databases inside an SQL Server at once, so they logically link in Sidra to the same Provider.
This change has been done in the metadata extraction pipeline of the SQL Server plugin. Now, in the SQL Server plugin, if a database is not specified, the default database is be taken as master, which now forces to loop through the whole list of databases inside the same SQL Server and extract metadata from all of them.
This greatly simplifies and streamlines the process of data intake, as now we can configure a data source where there is a big number of different databases sitting in an SQL Server with just a few steps.
Sidra CLI tool for installations and updates has been reviewed to ensure all commands are idempotent by default. This means that the different commands can be executed several times without needing to manually remove any data from Azure. This improvement minimizes the operational issues that can happen when there is any unexpected problem when running the commands. More specifically, the aadaplications command has been made idempotent, ensuring that all AAD applications are removed automatically before re-running the command, with no manual intervention required.
Sidra now incorporates an internal Provider containing relevant data sources originating internally in Sidra from tracing and operational modules.
The first version of this internal Sidra Provider includes the Log database in Sidra Core. Log database stores a copy of the logs (traces) of the platform, by applying a set of filters. There are several tables where the logs are located. This Provider improves the performance of Log database, by moving the older traces to the data lake (from which it can be queried and explored through Databricks). This allows optimizing the Log database by reducing the retention period in the database to the last 30 days. The full Log history is available in Databricks tables.
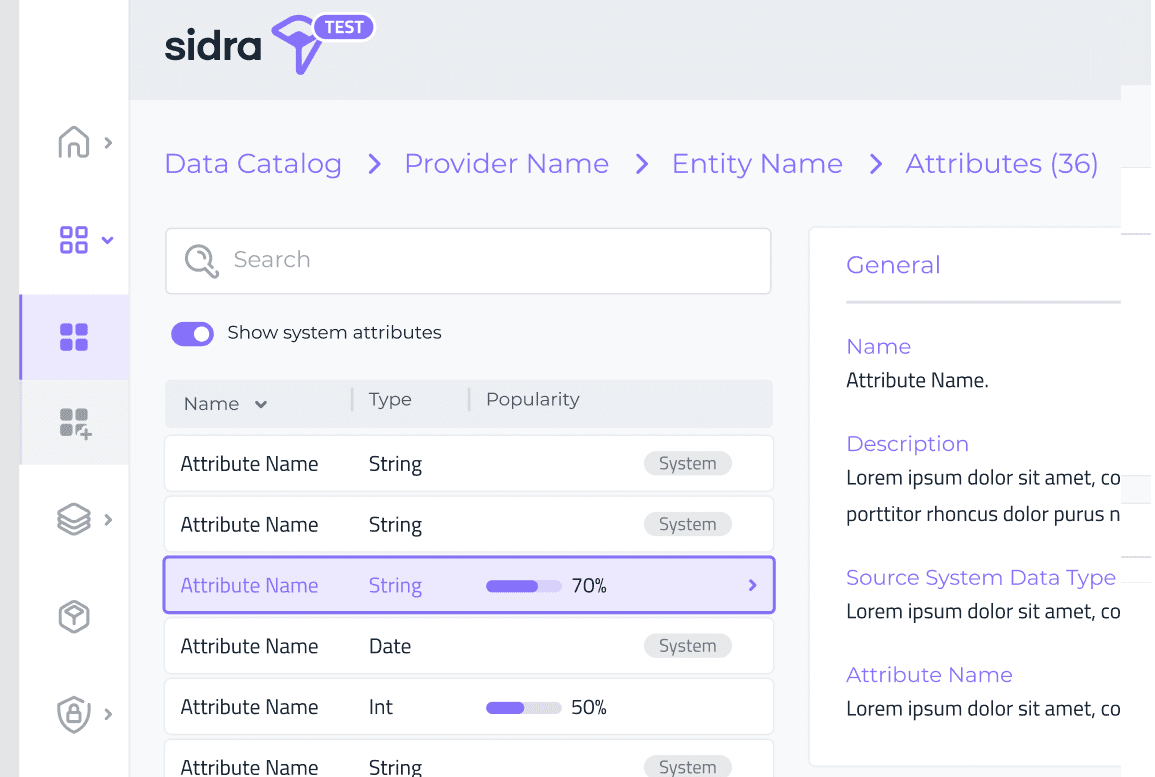
Sidra Data Catalog now includes the ability to see the popularity for all Attributes in the Attribute list and details page. Before this feature, just the top three Attributes popularity was displayed as a sample, in the Entity details page.
At Sidra, we are hugely interested in hearing your voice! We are pleased to launch with this release a new Sidra ideas portal. From this, you can suggest and vote ideas on Sidra roadmap. The ideas portal is also a great place to see what is coming and get a glimpse on mostly shared and voted ideas. We welcome your suggestions and feedback!
Sidra API now incorporates API endpoints to serve create, read, update and delete operations on EntityDeltaLoad table. This table is a key piece in Sidra metadata DataIngestion schema tables. This table fully tracks the needed data for managing incremental loads from source systems, which is independent of any native supported change tracking mechanisms.
See Sidra documentation for DataIngestion tables for more details about the structure and usage of this table.
Access to the complete list of resolved issues and relevant changes in Sidra 2021. R2, here.
This 2021.R2 has been a very important release for Sidra, as it has added new connector plugins using the previously released plugin model. But not only that: this release represents an important step towards making the existing pipelines and data ingestion robust enough to handle many new scenarios.
The architectural foundations for Client Applications plugin model, therefore, the ability to deploy Client Applications from the web, has also been achieved as part of this Sidra version. This lays down the path towards a streamlined way of packaging Client Applications so that its deployment is very simple to execute.
As part of the next release, we are planning to deliver our first Sidra-owned Client Application plugin, with a basic SQL Client Application as the first plugin of its type. Also, we plan to proceed further with the plugin model to allow further scenarios of plugin update configuration or plugin upgrades.
New plugins will be added to the gallery of connectors following a release cycle that no longer needs to be tied to Sidra Core release cycle.
Elena Canorea
Communications Lead
