
Elena Canorea
Communications Lead
During this latest release cycle, we have continued to put a big focus on the data intake plugins’ model and key building blocks to allow for a fully agile release cycle of plugins, decoupled as much as possible from Sidra release cycles.
This plugin model has been improved with the incorporation of the concept of Data Intake Process, described below.
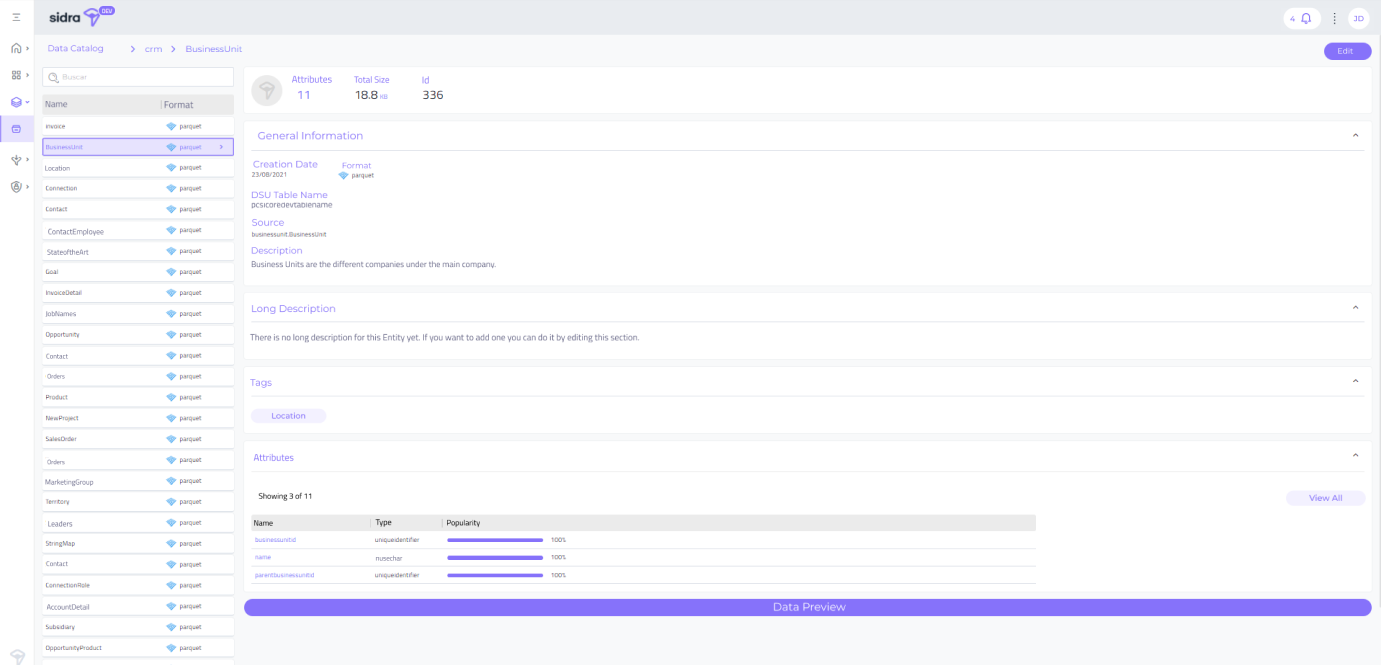
This release comes with a lot of improvement features on the Sidra Management Web UI, like the addition of tags to Attributes, and the ability to assign permission to Sidra roles from the web.
On top of that, deployment and operability improvements have been made, such as a reworked integration of logs and notifications with the Application Insights, support for feature toggling, or CLI enhancements.
The key features around plugins continue paving the way towards a full lifecycle for the configuration of processes related to data ingestion.
In the course of this latest release, we have continued to improve the data intake plugins model and setting the cornerstone to allow a full plugin management life-cycle for our users. Once this full life-cycle is completed, this will allow mainly:
It is also worth highlighting a new concept as the Data Intake Process, process which bridges the two worlds of plugin execution and underlying data intake infrastructure creation and operations.
Users are now able to access a new section of the web called Data Intake Processes to see the list of configured Data Intake Processes in any given Sidra installation.
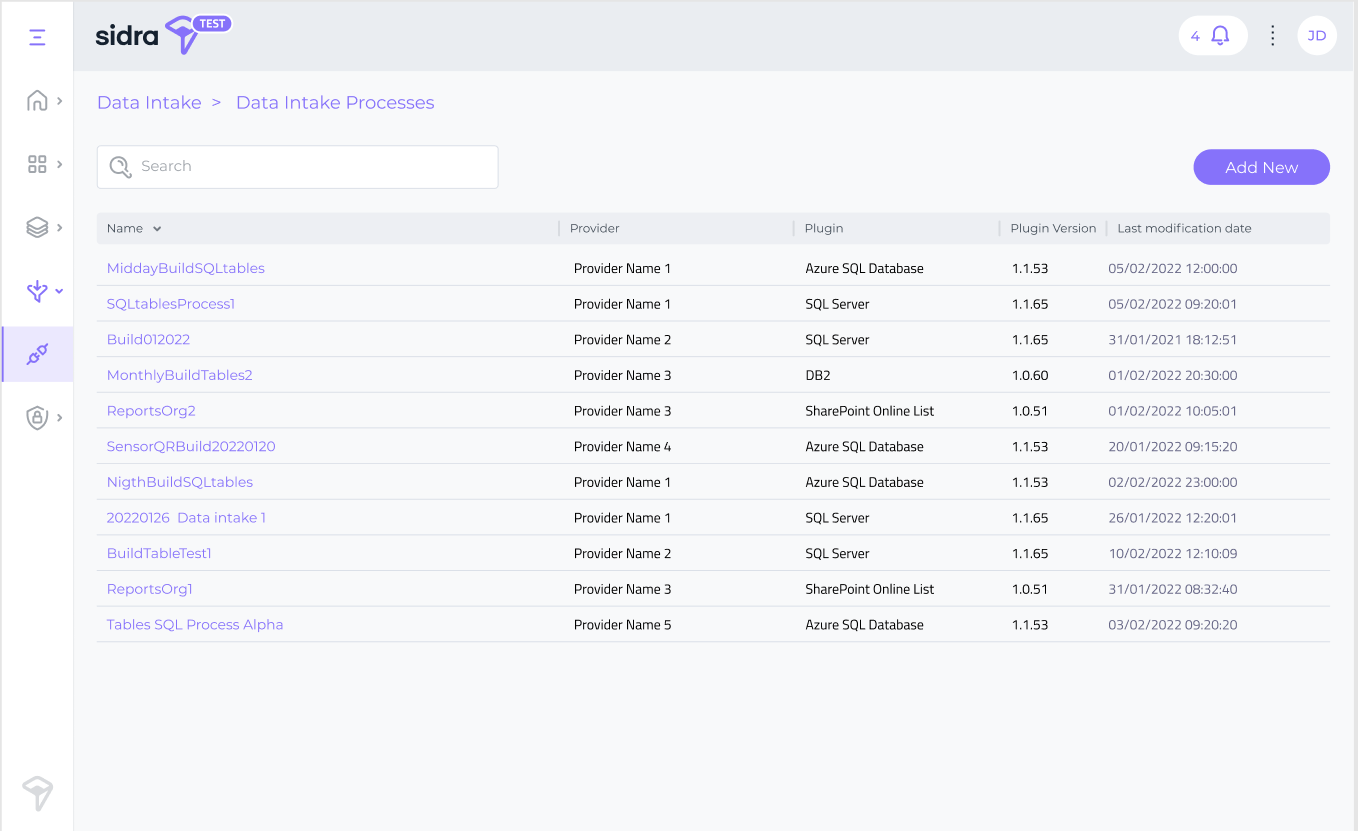
In a future release, from this list, users will be able to invoke actions such as update (the ability to re-execute the plugin with new configuration parameters), or upgrade to a new version of the plugin.
That brings us to the Connector Plugin concept. Every connector plugin execution will create a Data Intake Process object in Sidra, that in turn, will create the corresponding data integration infrastructure elements, the data governance structures and the metadata. The available connector plugins in this latest release of Sidra are Azure SQL connector, SQL Server connector and SharePoint online list connector.
A new automated migration process has been developed to convert the existing pipelines to the new Data Intake Model. This will be executed by our support team as part of the Sidra update process in this release 2022.R1.
Please, check on the Breaking Changes section for more information about the Data Intake Process migrations.
A new connector plugin for extracting and ingesting data from SharePoint online list data sources is released as part of this Sidra version.
This new connector plugin comes with several configuration options which cover different scenarios depending on the destination container and its relative file types.
This release incorporates a new Databricks Client Application template as an additional extension to the regular Basic SQL Client Application.
This template will cover different advanced scenarios where the user may require custom data query logic on the raw data lake or advanced data aggregation and dependencies logic.
A new process for data intake from Excel files has been implemented in Sidra in order to embrace the multiple scenarios coming from the users to do the consumption of their data properly. Thanks to this process now it is possible:
Thus, our Excel ingestion process is capable to infer the schema of the complex-formatted Excel files in order to define how to Entities and Views are going to be created, as well as how the data is going to be extracted.
Sidra Web UI incorporates in this release multiple functionality upgrades, redesigns and performance improvements.
Below is a list with all the improvements included as part of this feature:
 Support for multiple pipelines in Azure Search
Support for multiple pipelines in Azure SearchBefore this release, it was only possible to execute one pipeline per defined Entity in the binary file ingestion flow. The file indexing requires to process in parallel a set of files, so that they are indexed using different skillsets or indexing modules.
A data ingestion pipeline for Azure Search or binary file ingestion basically defines a skillset or indexing workflow to be executed over the files belonging to an Entity.
For supporting multiple simultaneous indexing workflows for the same Entity, the binary file ingestion module has been adapted to support a one-to-many relationship between Entities and data indexing pipelines. DSU tables and intermediate artifacts in Sidra like the Knowledge Store have been also adapted to support this multiple-pipelines scenario.
This support for multiple pipelines only applies to binary file ingestion.
For other types of data intake, like ingestion from structured or semi-structured data sources, the one-to-one relationship between Entity and data ingestion pipeline remains.
A new Sync behavior has been incorporated through a Sync webjob to be responsible for:
This new behavior is now more robust against possible errors during the Data Intake Process, where some of the Entities could be loaded while others not. With this release of Sidra, when this scenario happens, capturing and processing at the Client Application side is guaranteed to include all intermediate successful Assets into the Client Application synchronization. This applies to all Assets which are due to be ingested in the previous scheduled loads, up to the most recent day in which there are available Assets for every mandatory Entity.
The API now contains some parameters to enable custom table name prefix in the Databricks and the staging tables. This setting is disabled by default. If it is enabled, you can specify your own table name prefix, and if table prefix is empty, the resulting name will be just the name of the table at source.
These settings are the settings EnableCustomTableNamePrefix and CustomTableNamePrefix, and need to be used as parameters to call the metadata extraction pipeline.
Please, also read the breaking changes section for more information on different implementation alternatives.
We have updated to latest Databricks 10.3 runtime version, where Apache Spark is upgraded to version 3.2.1.
Sidra includes a broad range of possibilities to monitor and track the operational processes, especially during data intake: logs, notifications, KPIs in Sidra web and operational Power BI dashboard. In this new version, the product leverages the huge, centralized monitoring capabilities of Azure Application Insights to build upon the operability of the platform. With this release, all logs and notifications are sent to Application Insights, on top of the Azure Data Factory metrics. This enables the following:
Sidra now allows custom queries to be built using and combining these data sources to spot specific metrics relevant to users, at business or operational level.
In this release, we continue building upon the existing plugins and data intake pipeline templates as well as improving and adding new type translations between sources and Sidra components. More specifically, Oracle and SQL Server type mappings have been thoroughly reviewed and extended to cover for more scenarios.
As part of our ongoing effort on robustness and usability of the CLI tool, in this release we have included an enhancement whereby:
Sidra now uses Esquio to enable scenarios of feature toggling in Sidra. Esquio is a feature server integrated with Sidra backoffice, that allows to define features and apply different release / visibility of features based on a broad number of criteria. Further evolutions of Esquio will be explored to support complex access logic in Sidra Web UI and Sidra API.
Sidra architecture is continuously evolving to scale up and out according to growing roadmap requirements and customer needs. Modularity is a key principle of Sidra architecture, and the plugin model is one of the most important examples. In order to allow for a more decoupled evolution of data intake and the rest of the platform components, we have re-used the plugin model for a new use case. A new type of plugin, called pipelinedeployment , has been added to support versioning and easy installation of data intake pipelines even if they are not implemented by a full plugin on the web. This model is useful for versioning and installing bespoke data intake pipelines, outside as much as possible, of Sidra release life-cycle.
For the purpose of keep improving our transparency and support for the users, Sidra documentation website has included several guides in this new release:
Access to the complete list of resolved issues and relevant changes in Sidra 2022. R1, here.
This 2022.R1 release represents an important step towards making the existing pipelines and data ingestion robust enough to handle new scenarios.
Important steps have been taken to set the foundations for the plugin lifecycle model with the incorporation of the Data Intake Process concept, the operational improvements in managing plugins and the usage of the Entity Pipeline association also for plugins.
A new category of data ingestion from complex Excel files enables today a flexible and automated way to extract metadata structures from complex Excel worksheets.
Data querying from the lake has been completed with advanced scenarios of data querying and relationships between Entities.
Additionally, new plugins like the SharePoint connector plugin have been released, using the previously released plugin model. This completes a full end to end binary file ingestion user flow, just by configuring a few parameters from Sidra Web.
As part of the next release, we are planning to increase the plugin catalogue to create and edit Data Intake Processes from Sidra Web, with the release of new plugins for connector and Client Applications. New features for schema evolution and for improving binary file ingestion will also be incorporated.
Elena Canorea
Communications Lead
